We now support Image Diffusion Models! Read More...
The Open Source Platform for Training Advanced AI Models
With Transformer Lab, researchers, ML engineers, and developers can collaborate to build, study, and evaluate AI models—with provenance, reproducibility, evals, and transparency included.
Backed by Mozilla
Transformer Lab is proud to be supported by Mozilla through the Mozilla Builders Program

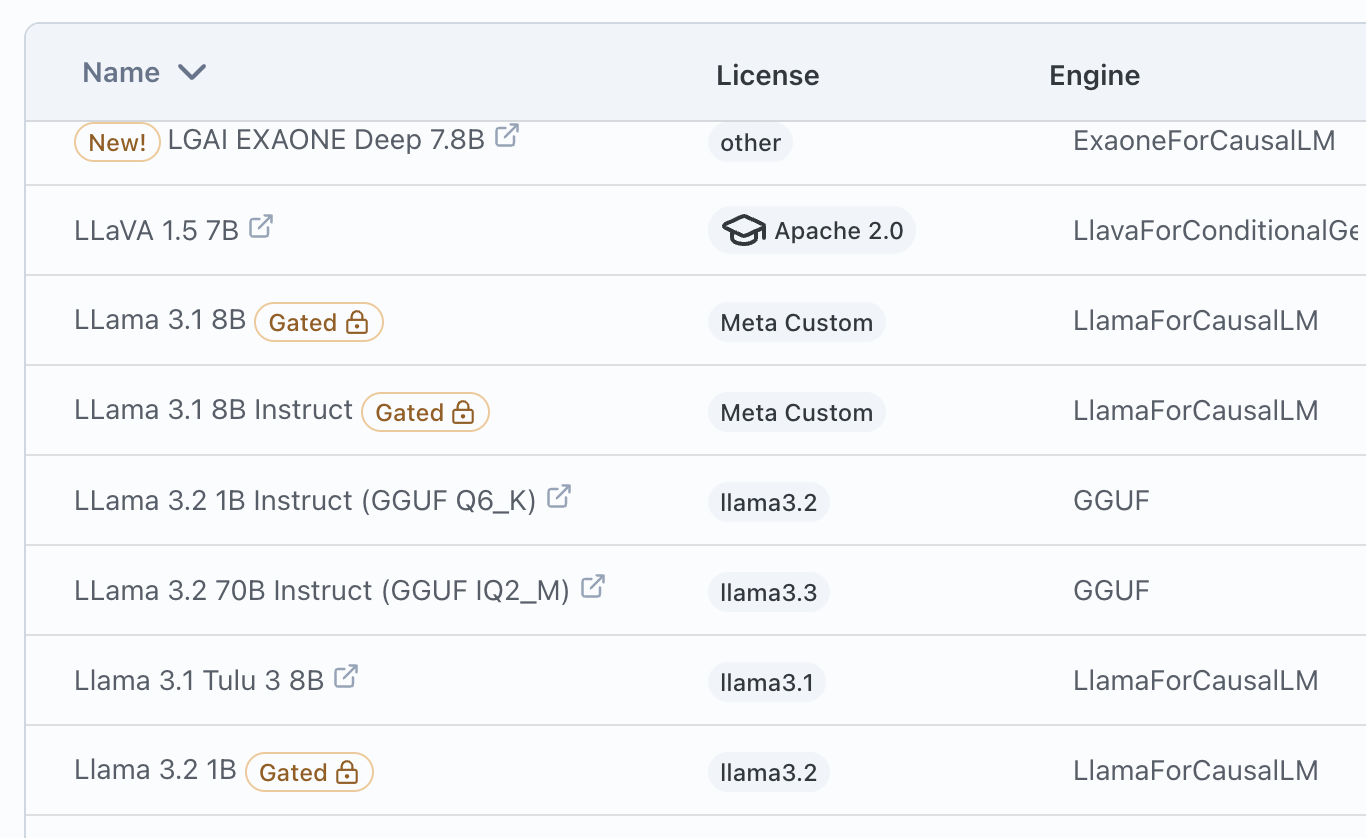
One-click Download Hundreds of Popular Models:
- Llama3, Phi3, Mistral, Mixtral, Gemma, Command-R, Stable Diffusion, Flux, and dozens more
- Download any LLM or Diffusion Model from Huggingface
- Train and use separate embedding models
- Convert between model formats (e.g. MLX, GGUF)
Chat with Models
- Chat
- Completions
- Preset (Templated) Prompts
- Chat History
- Tweak generation parameters
- Batch Inference
- Calculate Embeddings
- Visualize LogProbs
- Visualize Tokenizers
- Inference Logs
Generate and Train Diffusion Models
- Generate images on your own hardware using popular Diffusion Models like SDXL and Flux
- Inpainting and Img2Img
- Generate images using a dataset
- Train your own LoRAs
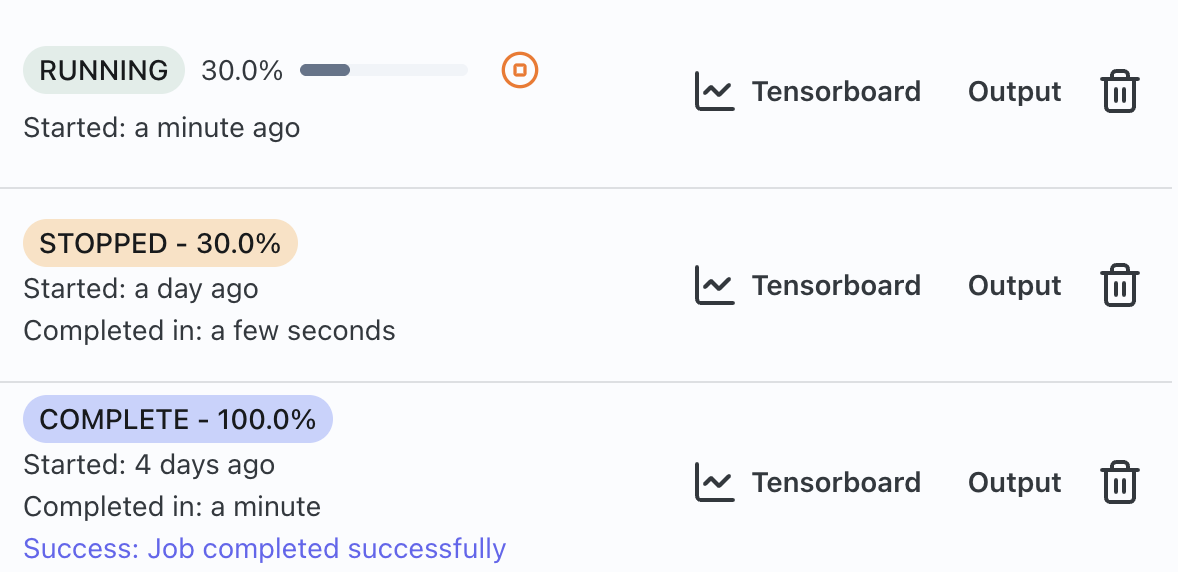
Pre-training, Finetuning, RLHF and Preference Optimization
- Train models from scratch
- Finetuning
- DPO
- ORPO
- SIMPO
- Reward Modeling
- GRPO
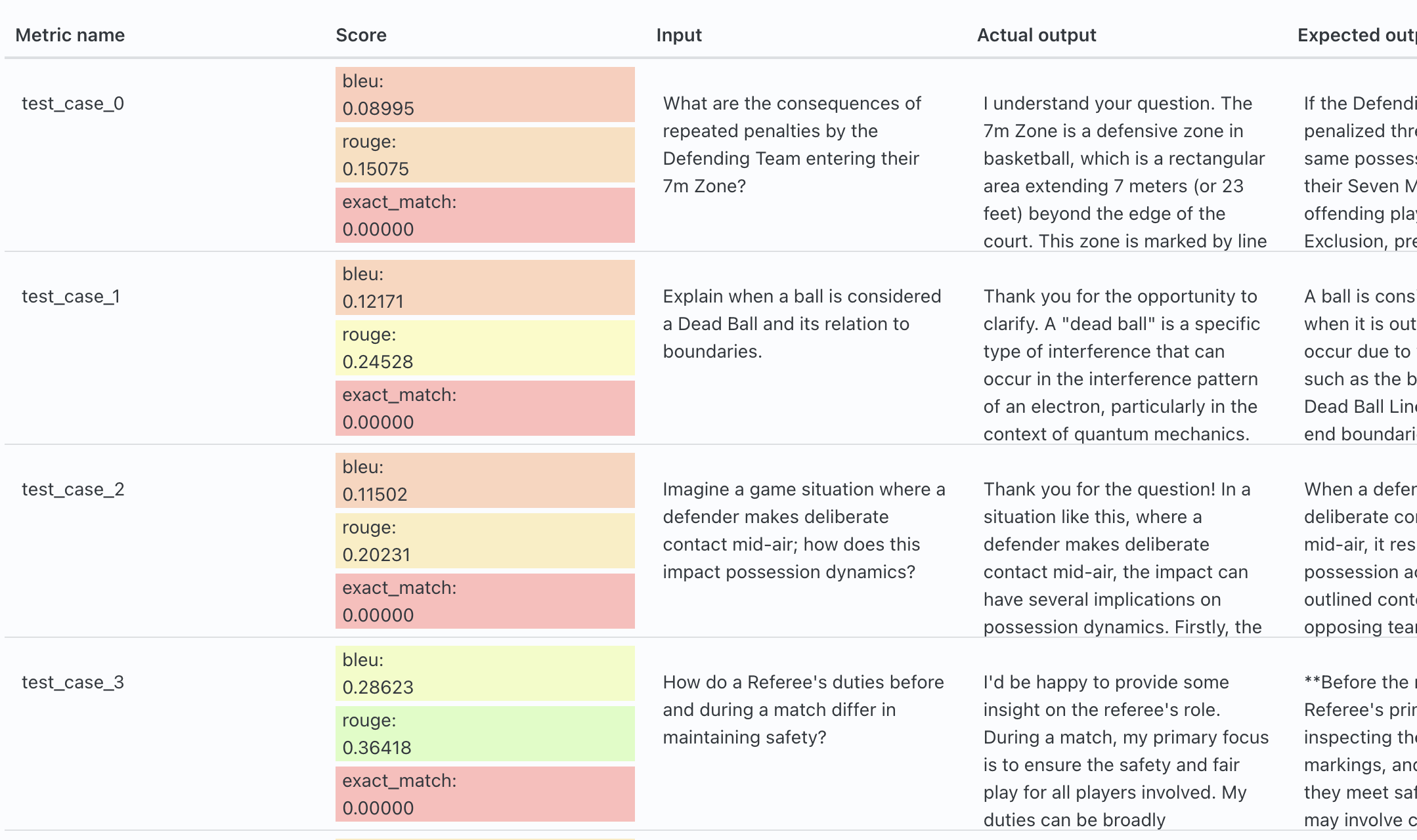
Comprehensive Evals
- Eleuther Harness
- LLM as a Judge
- Objective Metrics
- Red Teaming Evals
- Eval visualization and graphing
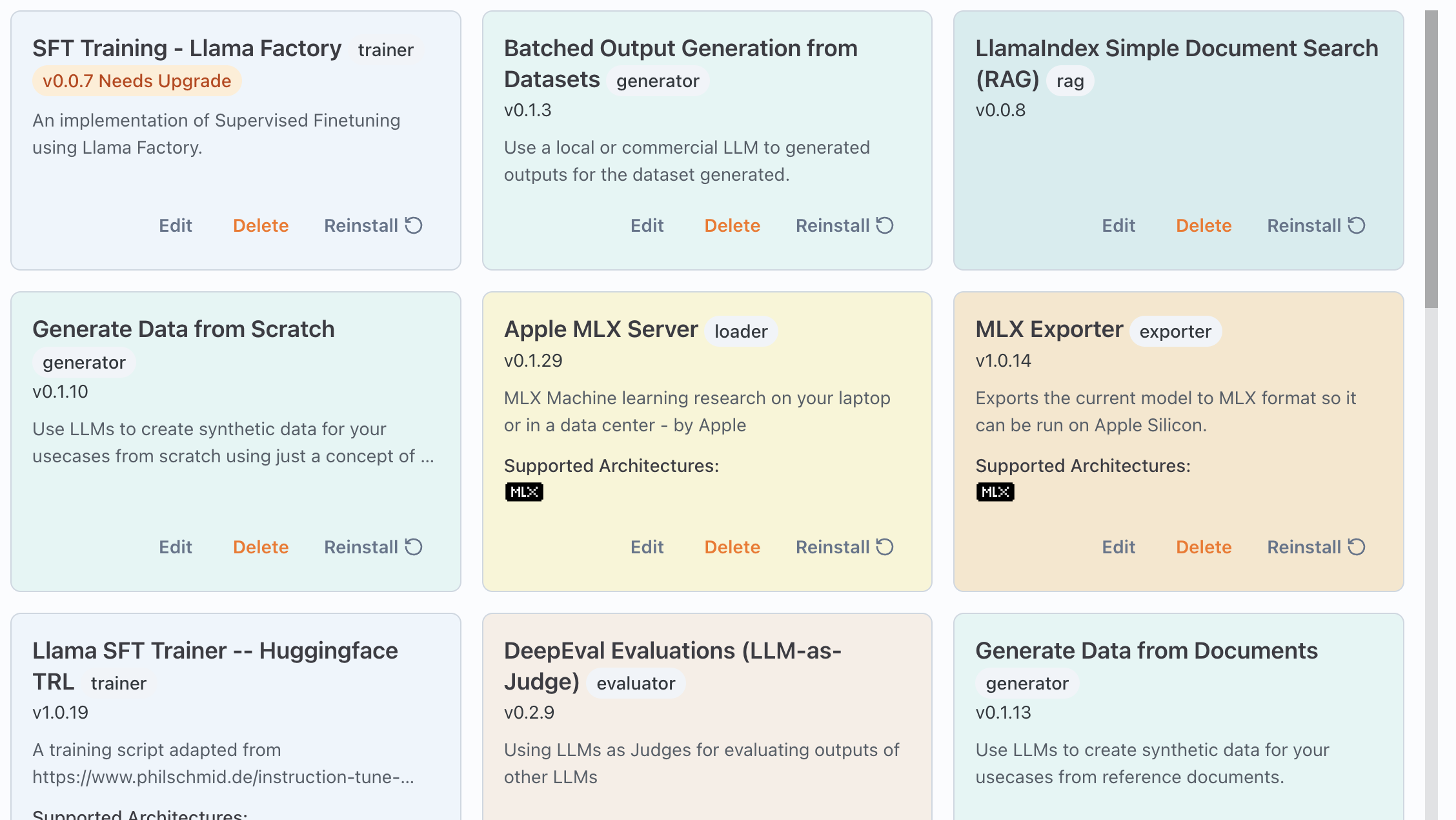
Plugin Support
- Easily pull from a library of existing plugins
- Write your own plugins to extend functionality
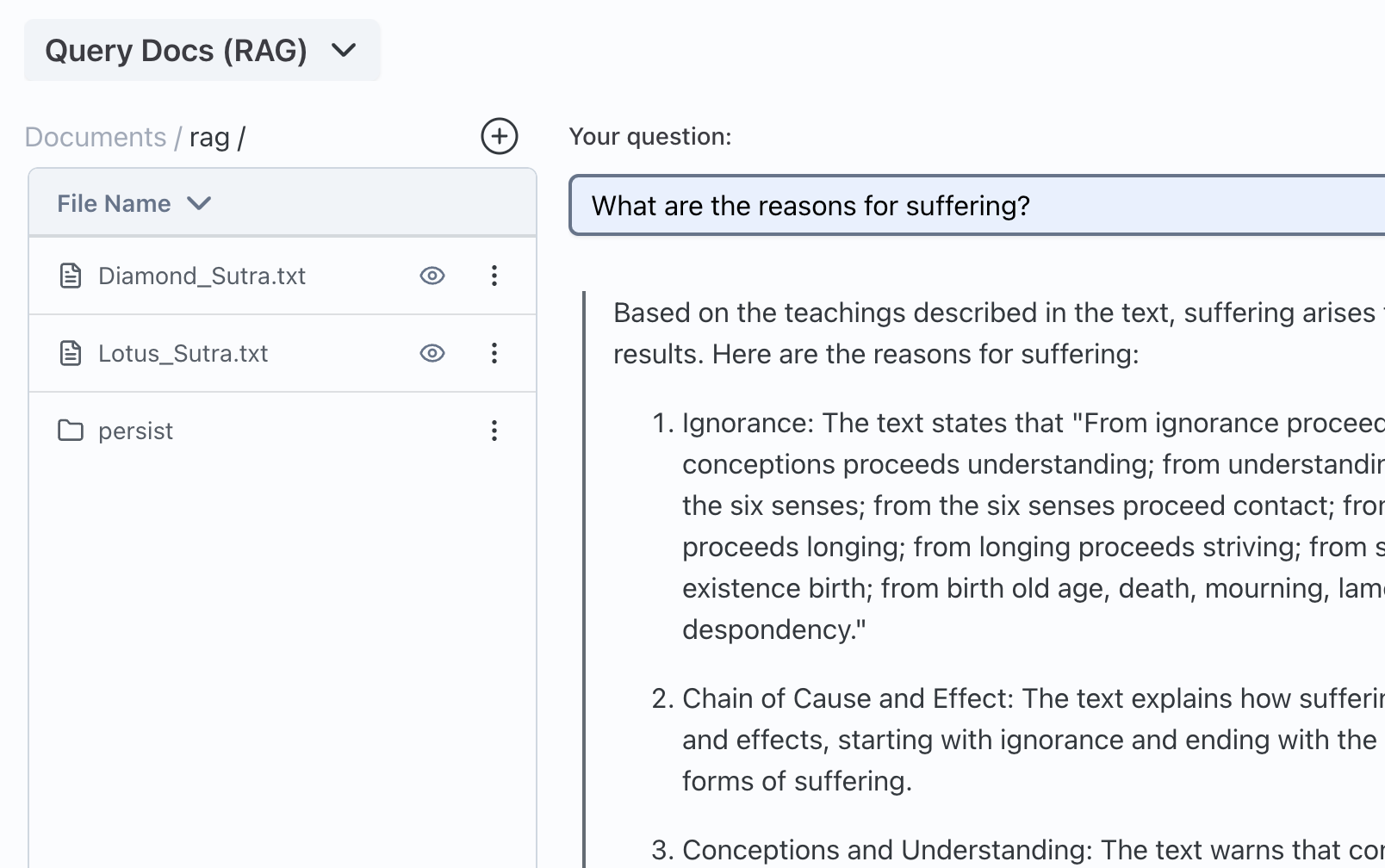
RAG (Retrieval Augmented Generation)
- Drag and Drop File UI
- Works on Apple MLX, HF Transformers, and other engines

Cross Platform, Cross GPU Support
- Windows, MacOS, Linux App
- Training and Inference using MLX on Apple Silicon
- Training and Inference using CUDA and ROCm
- Multi-GPU Training