Transformer Lab Can Talk Now: Introducing Text-to-Speech, Training & One-Shot Voice Cloning

🎉 Transformer Lab just got a voice! We’re thrilled to announce audio modality support so you can generate, clone, and train voices directly in Transformer Lab.
What’s included in this release
- 🎙️ Turn text into speech (TTS) with CUDA, AMD and MLX
- 🛠️ Train your own TTS models on CUDA and AMD
- 🧬 Clone a voice in one shot for lightning-fast replication on CUDA and AMD
🚀 Text-to-Speech on MLX
We’ve added TTS support to Transformer Lab’s MLX generation plugin, making it easier than ever to generate natural-sounding audio.
Here’s how you can try it today:
- Install the Apple Audio MLX Server plugin
- Pick a supported audio model in the Foundation tab
- Switch to the Audio tab
- Adjust your generation settings and start creating speech instantly!
🎧 Supported Model Families
We currently support several powerful TTS model categories. Here are a few examples you can try right now:
- Kokoro → mlx-community/Kokoro-82M-4bit
- Dia → mlx-community/Dia-1.6B
- Spark → mlx-community/Spark-TTS-0.5B-bf16
- Bark → mlx-community/bark-small
- CSM → mlx-community/csm-1b
👀 Watch It in Action
Here’s a quick demo showing how simple it is to generate speech in Transformer Lab using Kokoro-82M-4bit:
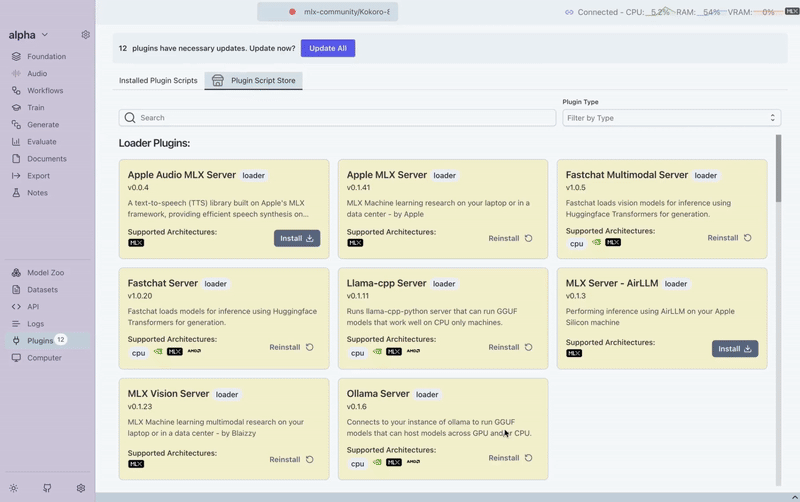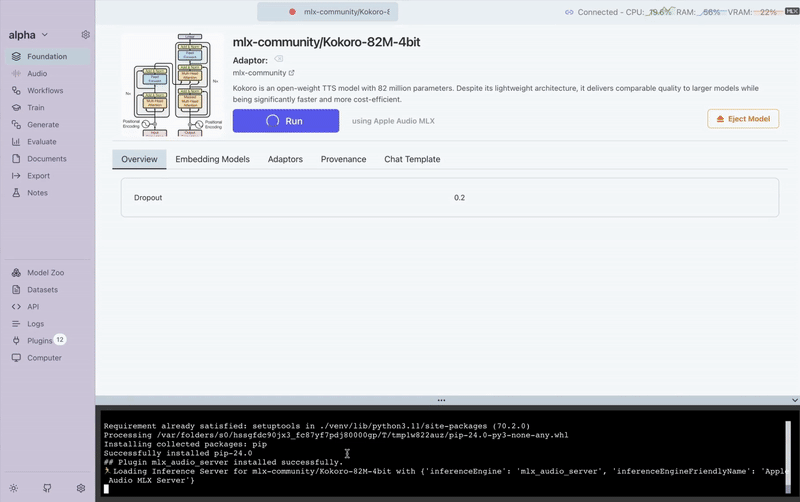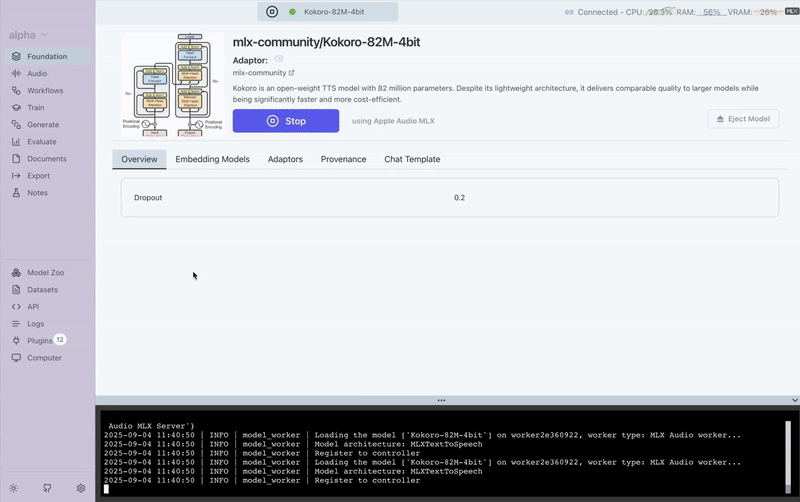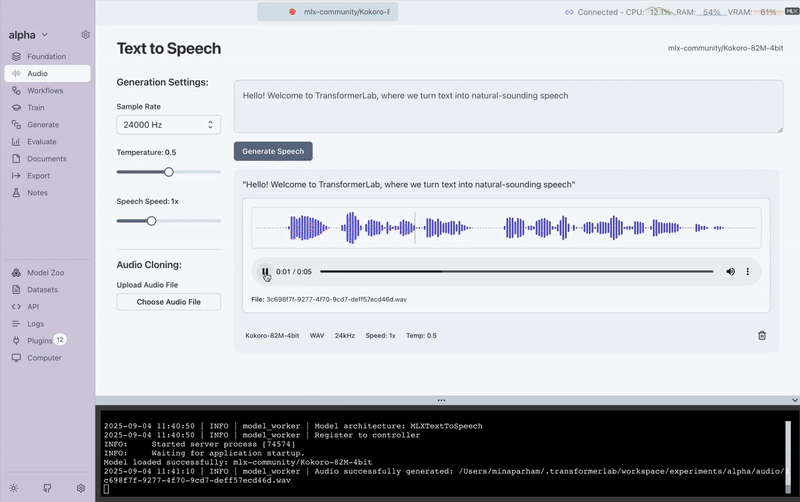
In just a few clicks, we went from plain text to lifelike audio. For this example, we used the sentence:
“Hello! Welcome to Transformer Lab, where we turn text into natural-sounding speech.”
🎛️ MLX Generation Parameters
When you generate audio with the MLX plugin, you’ll see a set of parameters you can adjust to customize the output. Here’s what each one does:
- text → The input string you want to convert to speech.
- Sample Rate → Number of audio samples per second; higher rates mean clearer, more detailed audio.
- Temperature → Controls randomness in speech; lower = consistent, higher = more expressive and varied.
- Speech Speed → Adjusts how quickly the text is spoken: slower for clarity, faster for natural pacing.
⚡ Text-to-Speech & One-Shot Cloning on CUDA and AMD
On CUDA and AMD, you can perform one-shot audio cloning replicating a voice instantly from just one reference sample
Here’s how you can try it today:
- Install the Unsloth Text-to-Speech Server plugin
- Pick a supported audio model in the Foundation tab
- Switch to the Audio tab
- Adjust your generation settings and start creating speech instantly!
🎧 Supported Model Families
- Orpheus → unsloth/orpheus-3b-0.1-ft
- CSM → unsloth/csm-1b
👀 Watch It in Action
Here’s a quick demo showing how simple it is to generate speech in Transformer Lab using unsloth/orpheus-3b-0.1-ft:
First, here’s the model generating speech directly from text:
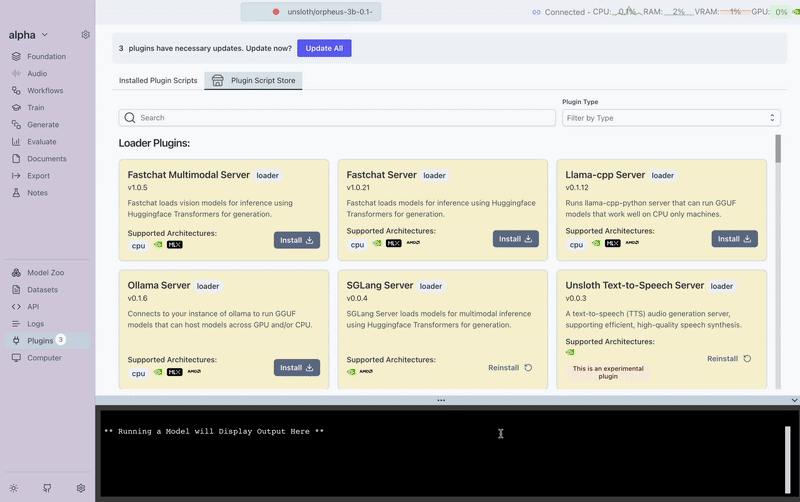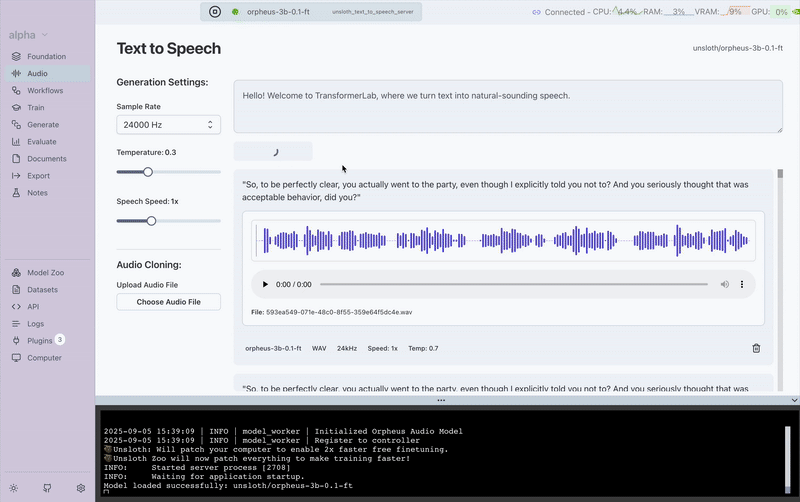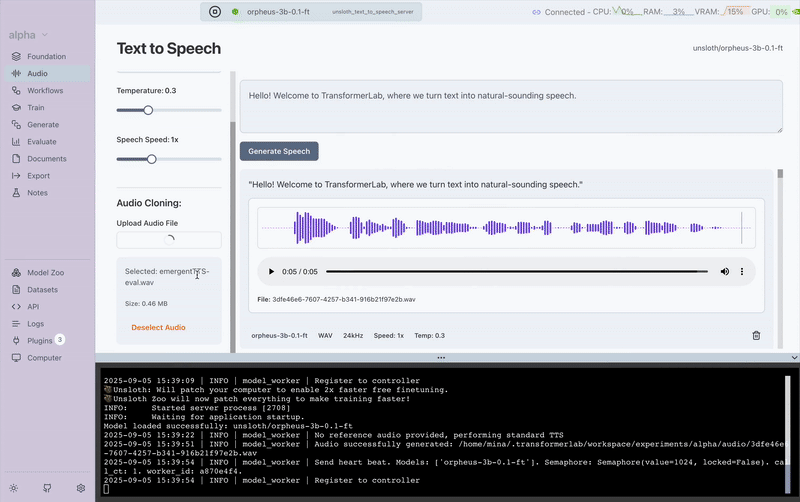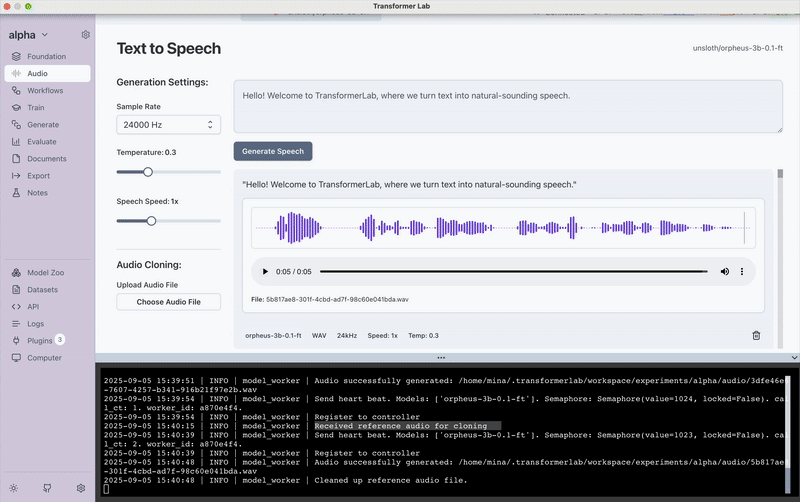
Next, we provided a single sample of the target voice we wanted to clone:
Finally, here’s the result — the model speaking the same sentence, but now in the cloned voice:
🏗️Training Your Own TTS Model on CUDA and AMD
While one-shot cloning is powerful, you can take it even further by training a model directly on the target voice. This gives the model more examples to learn from, resulting in more consistent and natural-sounding speech.
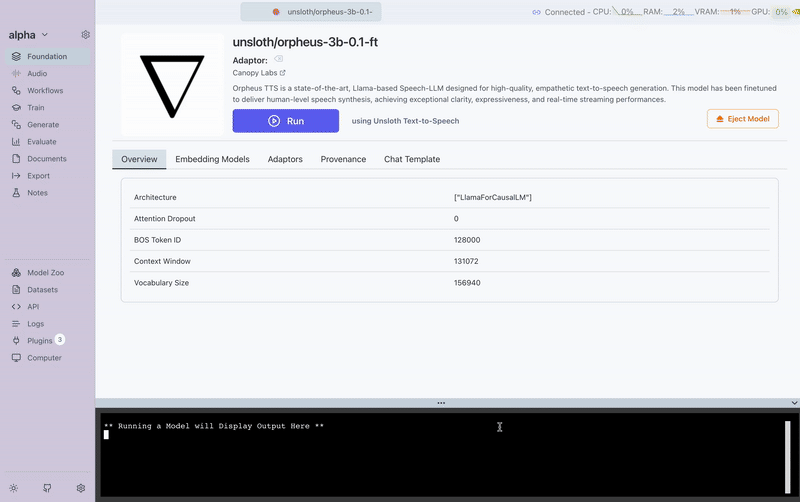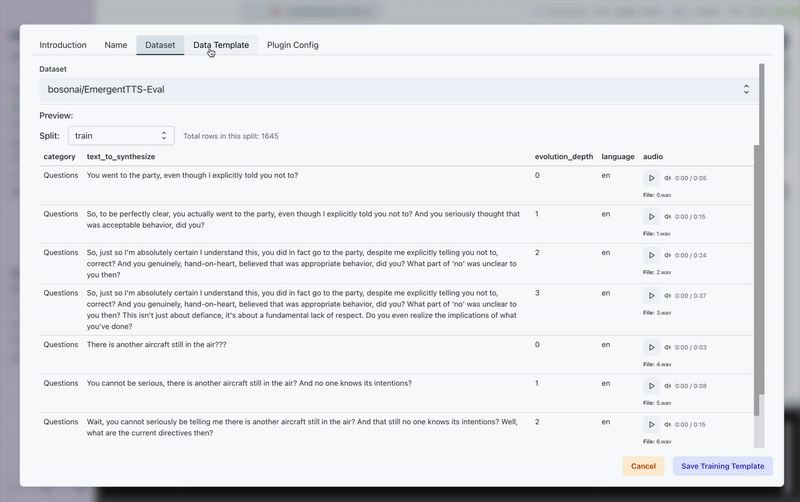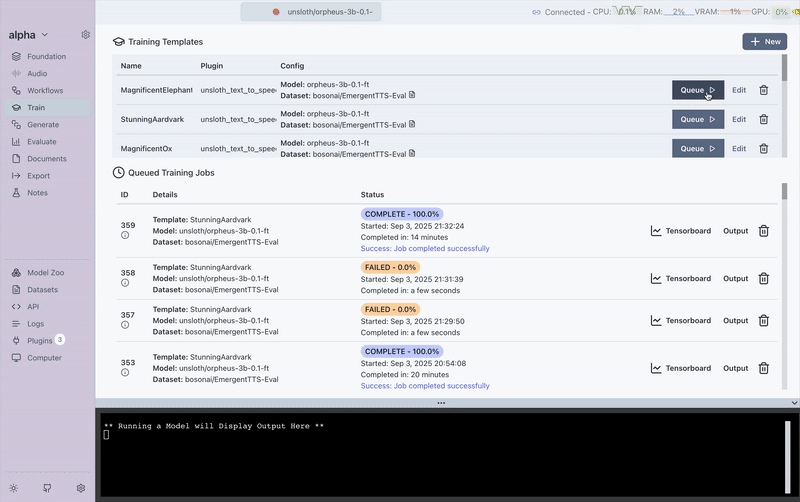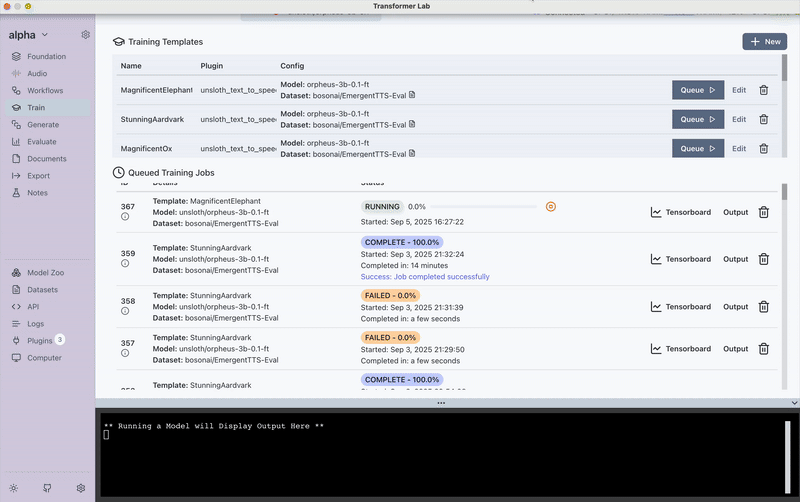
For this demo, we used the bosonai/EmergentTTS-Eval dataset and trained a custom TTS model inside Transformer Lab.
🎛️ Training Parameters
Here are some of the key parameters you’ll see in the training configuration tab:
- Sampling Rate → Audio sampling frequency
- Audio Column Name → Dataset column containing audio files
- Text Column Name → Dataset column containing transcriptions
For a complete list of training parameters and detailed explanations, see the Text-to-Speech Training Documentation.
👀 Watch It in Action
To compare, here are three samples: Before training — the model’s default voice generating our sentence:
Sample from dataset — a real voice clip the model trained on:
After training — the model reproducing the same sentence in the target voice:
We’re just getting started with audio support in Transformer Lab, and we want to make sure we’re adding the models that matter most to you. 🎙️
👉 Which text-to-speech or voice cloning models would you like to see supported next?
Drop your suggestions in our Discord community — we’re always listening and excited to hear your ideas.


