Building and Evaluating a RAG Pipeline in Transformer Lab

Retrieval-Augmented Generation (RAG) combines the power of retrieval systems with generative AI to create more accurate, factual, and contextually relevant responses. In this hands-on tutorial, we'll walk through building and evaluating a complete RAG pipeline in Transformer Lab using documentation files as our knowledge base.
What We'll Build
In this tutorial, we will:
- Use three .md documents from the Transformer Lab documentation
- Generate a RAG QnA dataset from these documents
- Fine-tune the
BAAI/bge-base-en-v1.5embedding model - Compare RAG results between the pre-trained and fine-tuned embedding models
- Evaluate performance using contextual precision and answer relevancy metrics
Let's get started!
Step 1: Upload Your Documents
First, we'll upload three markdown documentation files from the Transformer Lab project.
- Navigate to the Documents tab in Transformer Lab
- Create a new folder called
rag - Upload the following three .md files from our documentation:
docs.mdscratch.mdraw_text.md
These files contain detailed information about the three synthesizer plugins (Generate from Documents, Raw Text and Scratch) in Transformer Lab.
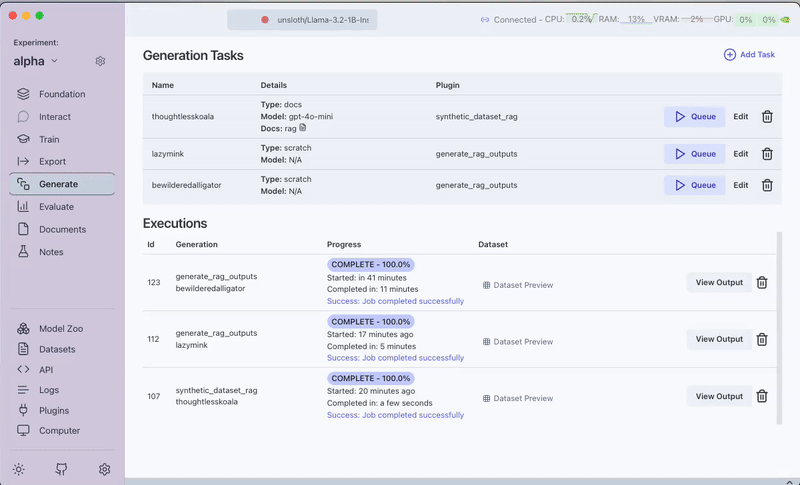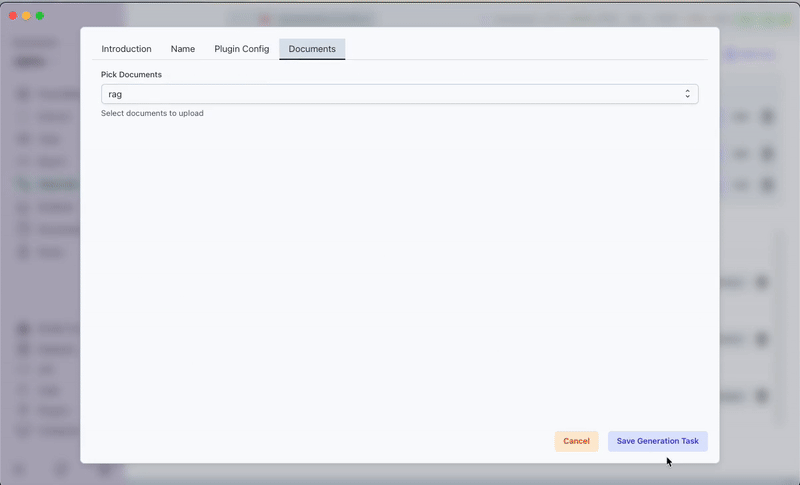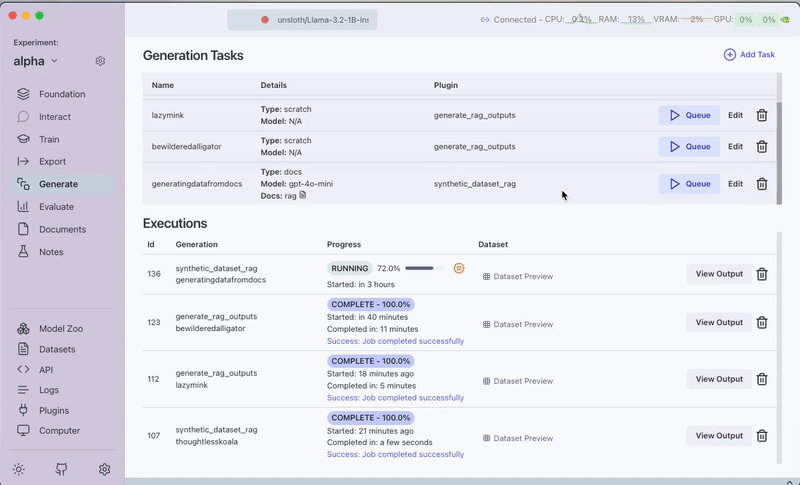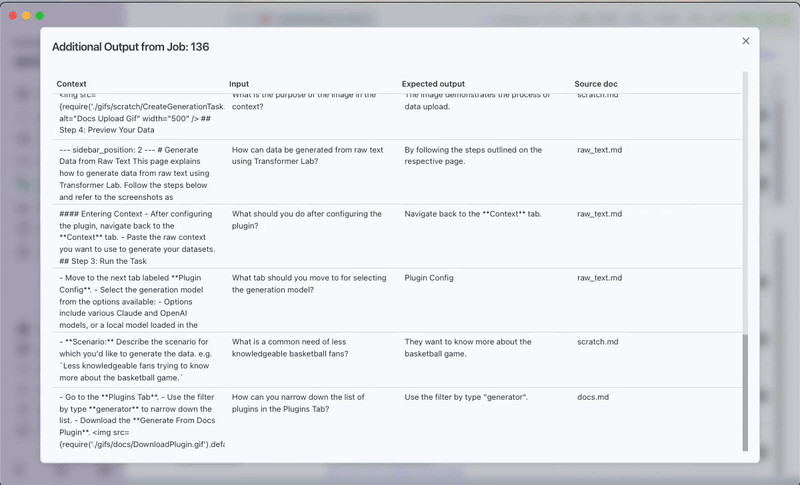
Step 2: Generate a RAG Q&A Dataset
Next, we'll create a dataset of questions and answers based on our documentation files.
- Navigate to the
Generatetab - Select
Generate Dataset with QA Pairs for RAG Evaluationplugin - Configure the plugin task:
- Documents:
rag - Number of QA pairs: 20
- Generation Model: GPT-4o-mini
- Documents:
- Generate the Q&A pairs automatically
The generated dataset will contain questions that span different aspects of the documentation.
Step 3: Fine-tune an Embedding Model
Now we'll fine-tune the BAAI/bge-base-en-v1.5 embedding model on our documentation.
- Go to the
Traintab. - Select the
Embedding Model Trainerplugin. - Configure the fine-tuning parameters:
- Dataset: Your generated RAG QnA dataset
- Dataset Type:
single sentences - Loss Function:
DenoisingAutoEncoderLoss - Text Column Name:
context
- Start the fine-tuning process
We're fine-tuning on our specific documentation domain to improve retrieval performance on Transformer Lab-related queries.
Step 4: Select Your Embedding Model
After fine-tuning, we'll test both the original and fine-tuned models:
- Navigate to the Foundation tab
- First, select the original "BAAI/bge-base-en-v1.5" model from the dropdown
- We'll run tests with this, then switch to our fine-tuned model later
By selecting the embedding model in the Foundation tab, we tell the system which embeddings to use for our RAG pipeline.
Step 5: Configure the Model Server
Let's run the model server with our selected embedding model:
- Ensure the original "BAAI/bge-base-en-v1.5" model is selected in the Foundation tab
- Run the model server to use for the RAG pipeline.
- Wait for confirmation that the server is running successfully
The model server needs to be running for the RAG pipeline to generate embeddings for our documents.
Note: If you haven't used RAG before on the app, then you will have to download a RAG plugin such as
LlamaIndex Simple Document Search (RAG)from the Plugins Tab. We also strongly recommend that you initialize RAG once by just running the model and navigating toInteract > Query Docs (RAG)and selecting and setting the RAG engine there so you see a page which prompts you ask questions. This will ensure that the RAG engine is initialized and ready to use. You can then move to the next step for generating RAG answers.
Step 6: Generate Answers Using RAG with the Pre-trained Model
Now we'll test our RAG pipeline using the original pre-trained embedding model:
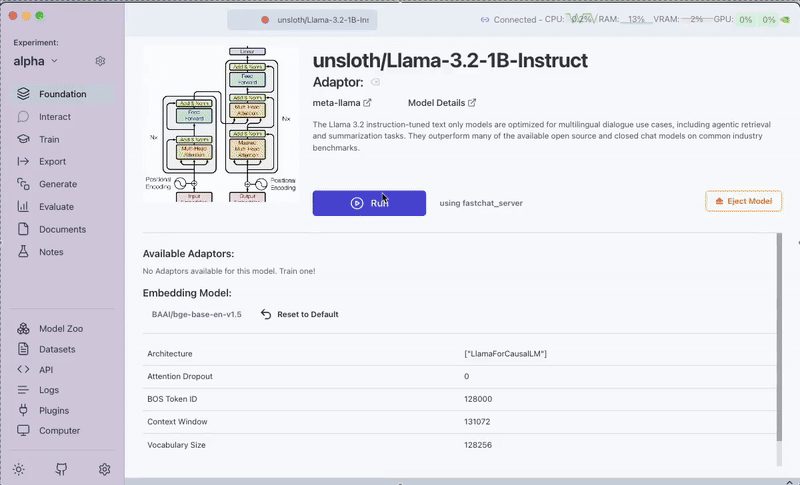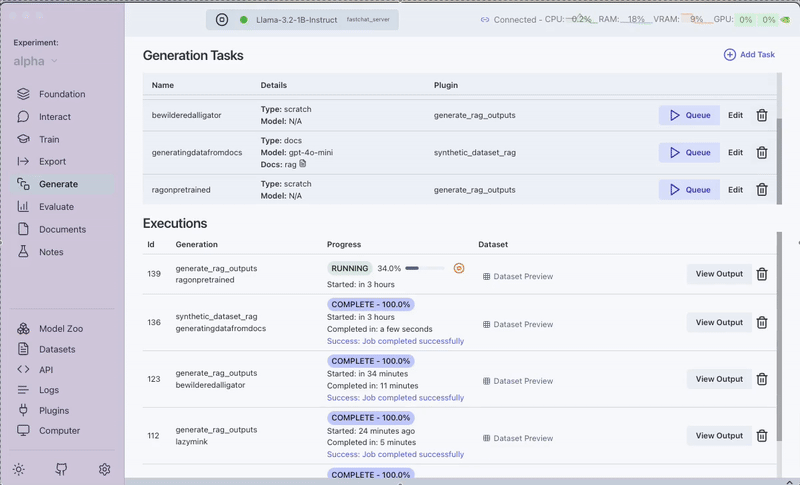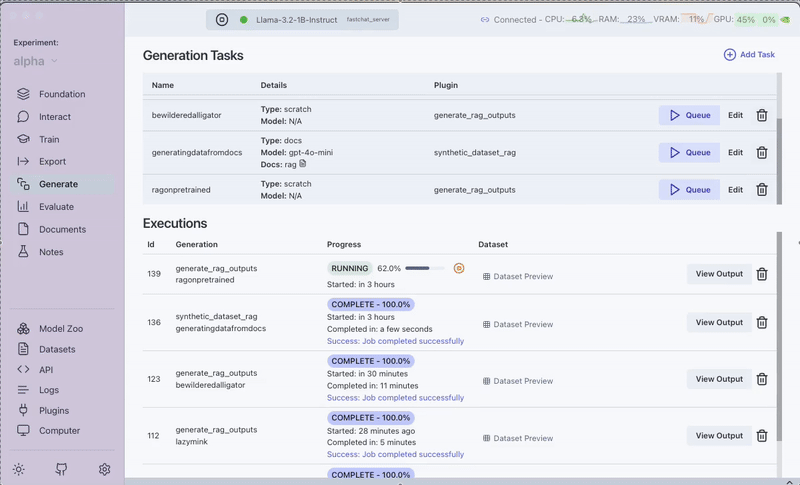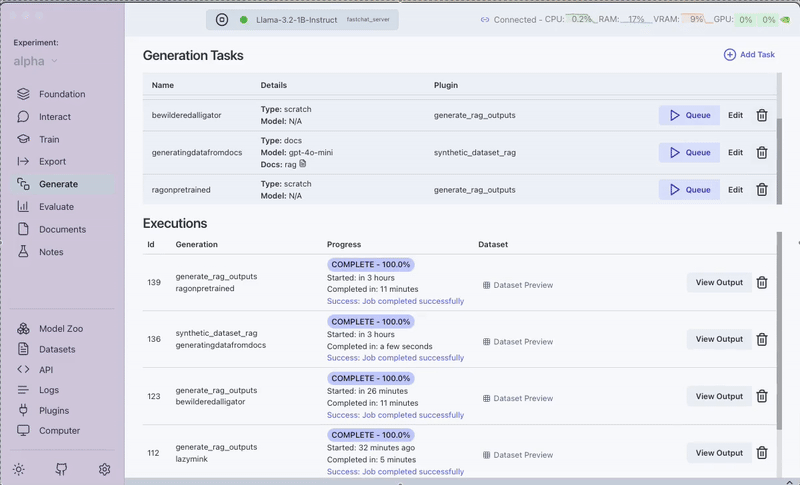
- Go to the Plugins section
- Select the "RAG Batched Outputs Generator" plugin
- Select the generated dataset in Step 2 (The plugin automatically uses the BAAI/bge-base-en-v1.5 model we selected in the Foundation tab)
Step 7: Switch to the Fine-tuned Model and Compare Results
Now let's repeat the process with our fine-tuned embedding model:
- Return to the Foundation tab
- Select your fine-tuned version of "BAAI/bge-base-en-v1.5"
- Restart the model server with this new model
- Run the same queries through the "RAG Batched Outputs Generator" plugin
- Compare the results from both models
This comparison will help us understand how fine-tuning improves or degrades retrieval quality for our specific documentation domain.
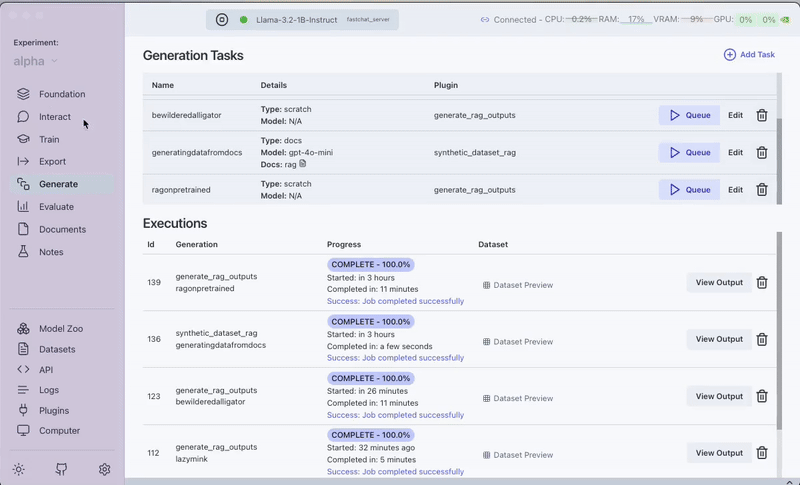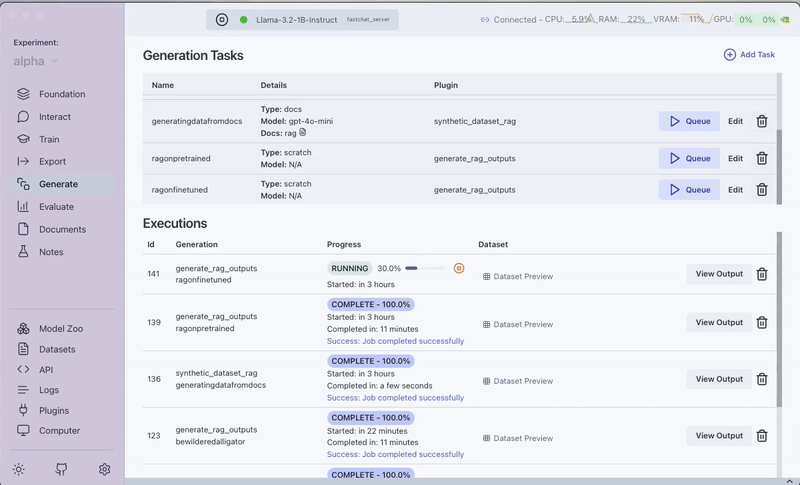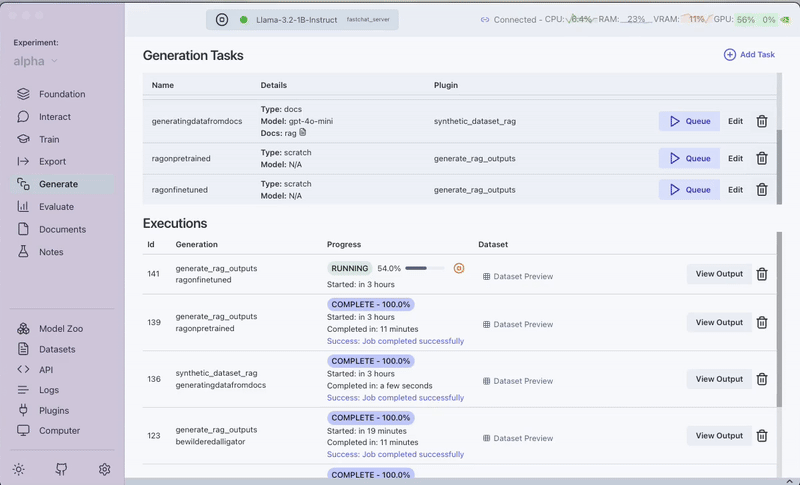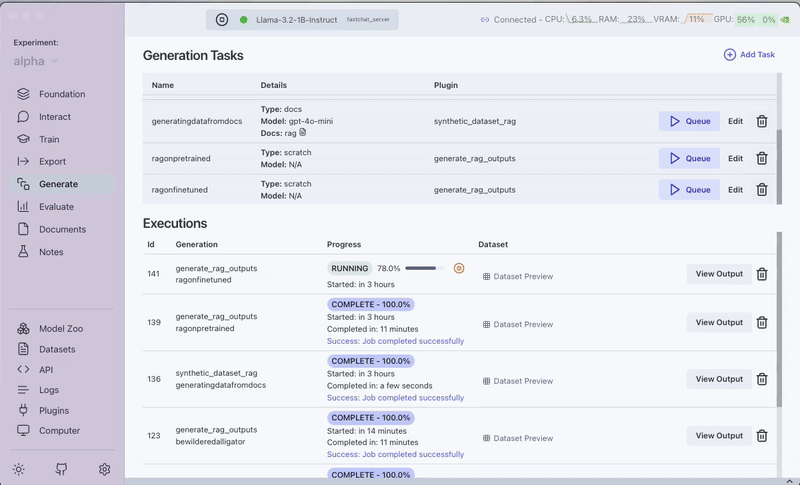
Step 8: Evaluate Performance
Finally, let's quantitatively evaluate both models:
- Go to the Plugins section
- Select the "DeepEval Evaluations (LLM-as-Judge)" plugin
- Create a task for each RAG outputs generation
- Task 1: Pre-trained model results
- Task 2: Fine-tuned model results
- Configure the evaluation:
- Metrics: "Contextual Precision" and "Answer Relevancy"
- Dataset: Results from the RAG outputs
- Run the evaluation and analyze results and compare them
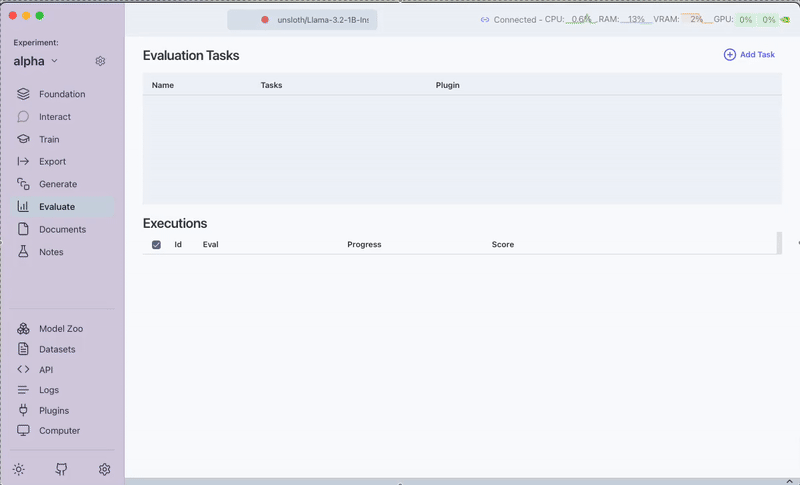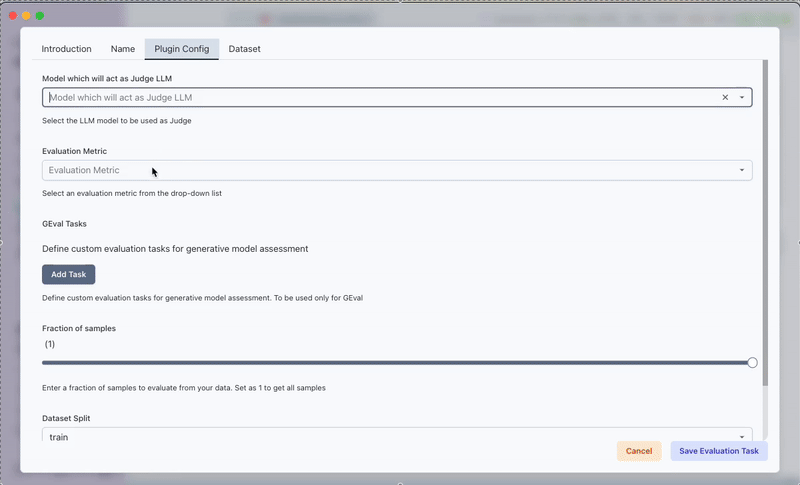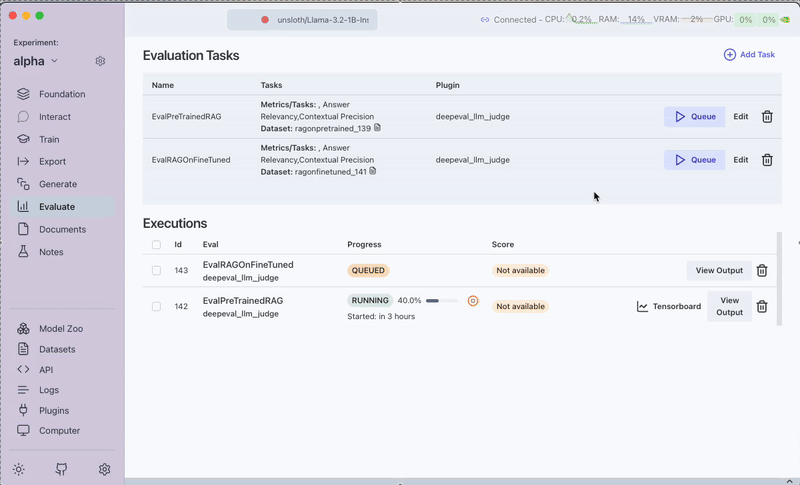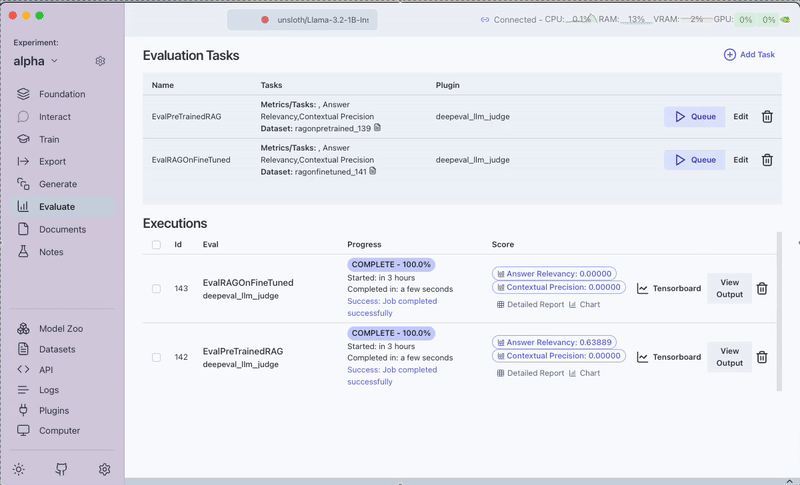
The evaluation results will show us how fine-tuning affects:
- Contextual Precision: How accurately the retrieved content matches the query context
- Answer Relevancy: How relevant the generated answers are to the original questions
Results Analysis
The specific improvements will vary based on your fine-tuning parameters, size of the data and documentation content. We get lower scores because we fine-tuned the embedding model on only 20 QnA pairs which degraded the embedding model.
Conclusion
In this tutorial, we've built a complete RAG pipeline using Transformer Lab documentation, fine-tuned an embedding model, and quantitatively compared performance between pre-trained and fine-tuned models.
This approach demonstrates how domain-specific fine-tuning can affect RAG performance for specialized knowledge bases. By following these steps, you can create and evaluate your own custom RAG solutions for any domain-specific use case.