Plugins
Introduction
Plugins extend the functionality of Transformer Lab, giving it more options for inference, training, or evaluations.
Plugins are just python scripts that are called by Transformer Lab.
Contents of Plugin
A full plugin contains at least three files:
index.json-- which defines the contents of the pluginmain.py-- which defines the scriptsetup.sh-- which is run once when the plugin is installed. It can install depedencies (often by calling pythonpip)
You can view an example plugin to use as a template at:
How Plugins are Installed and Where They are Stored
When Transformer Lab is started, it copies all the sample plugins that are stored at ./transformerlab/plugins/ to ./workspace/plugins
The plugins at ./workspace/plugins/ are available to be installed to any experiment by going to Experiment->Plugins Script Store and clicking on Install
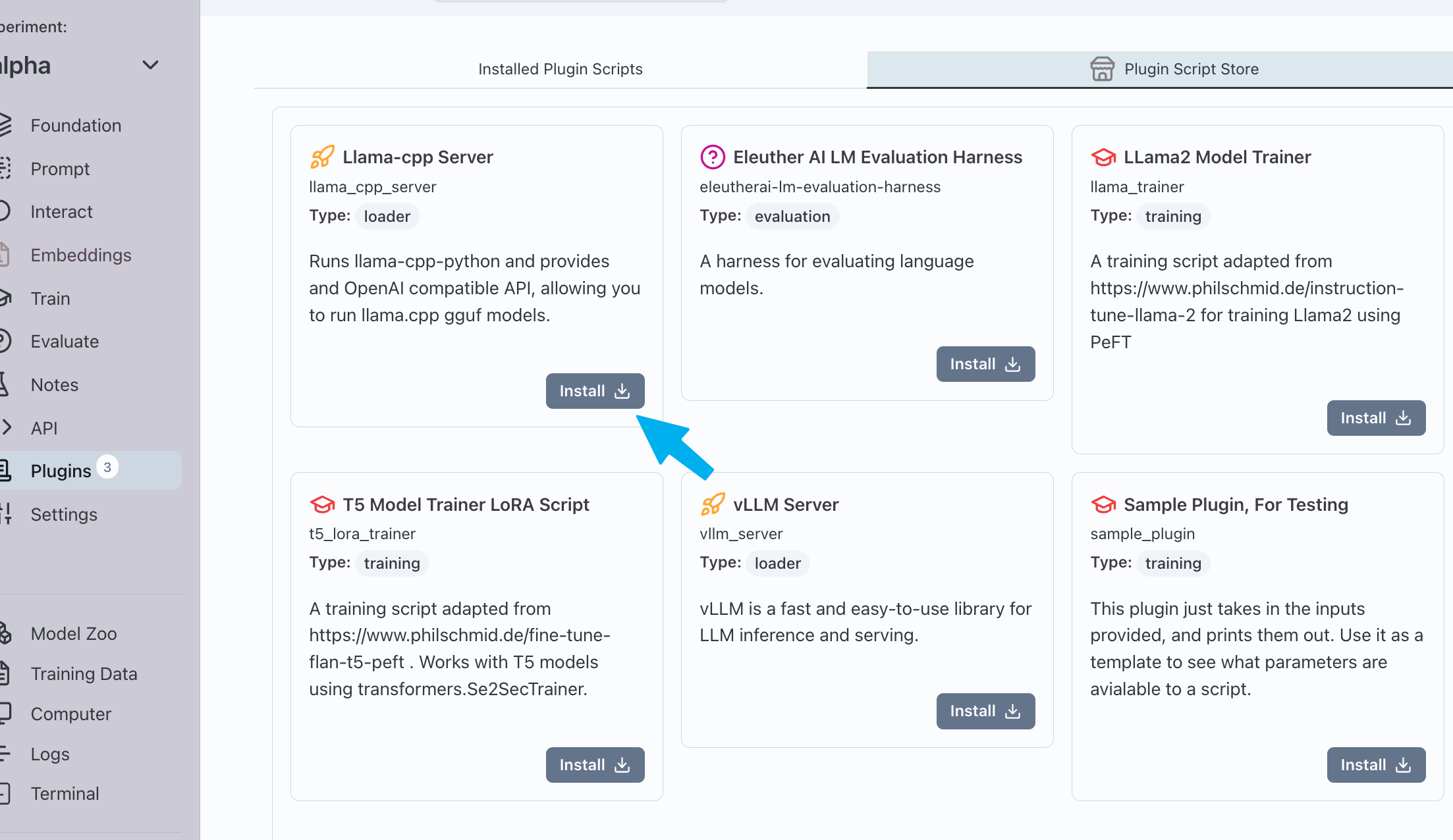
Additional plugins, that are not included by default, are also listed and can be installed in the same way.
Note that in the current version of Transformer Lab, all plugins are stored per experiment. There is no concept of a "global plugin" that is shared by all experiments.
Editing Plugins
Once a plugin is installed to an experiment, you can edit the contents of the script by going to Plugins->Installed Plugin Scripts and then clicking on Edit on any specific plugin.
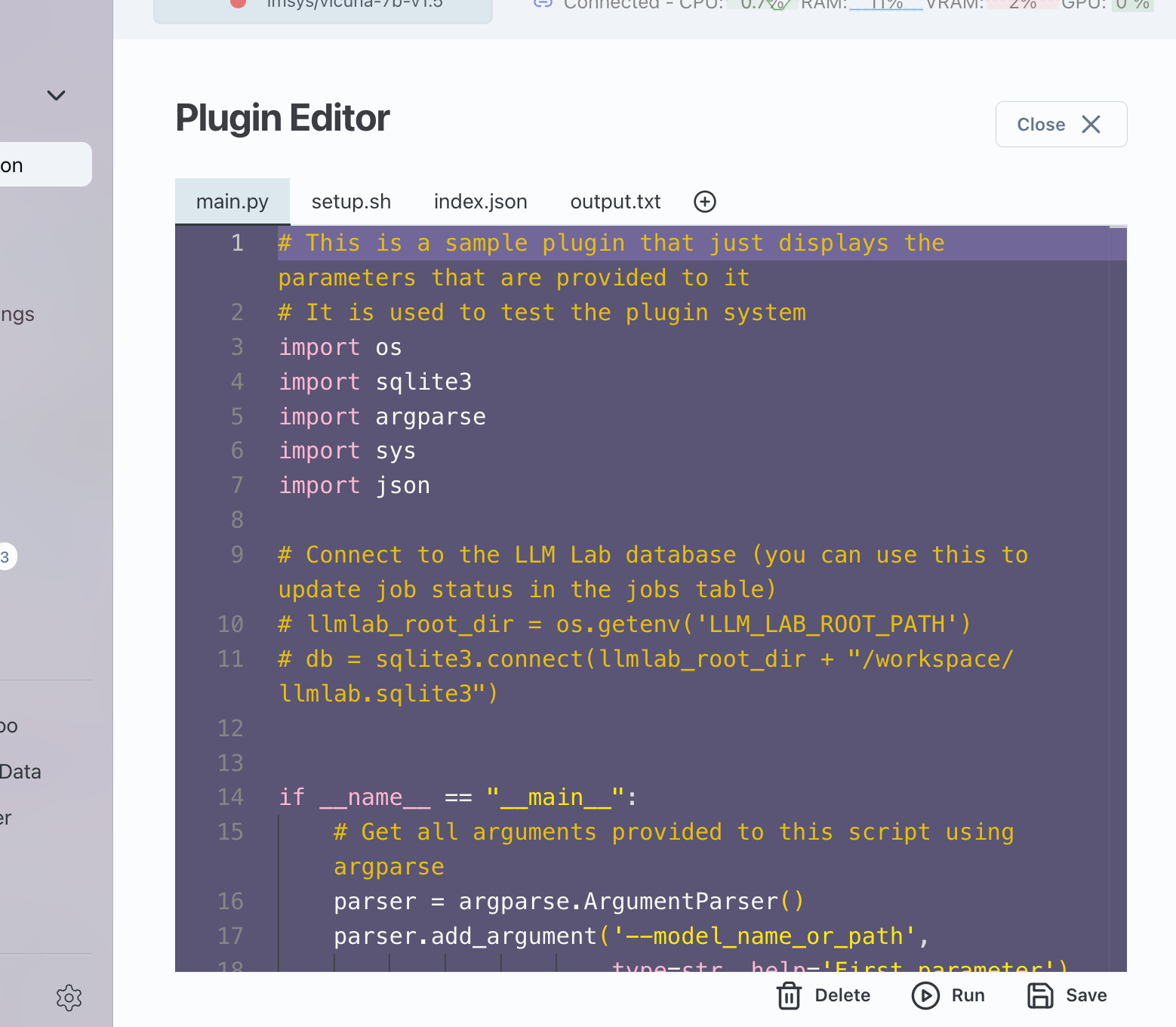
Editing a plugin will only edit it for that specific experiment because each plugin is copied to an experiment when it is installed.
Creating new Plugins
If you would like to create a new plugin only for yourself, you can create it at ./workspace/plugins and it will be available to all your experiments.
If you would like to share your plugin with others users of Transformer Lab, we would love if you submitted it to the gallery by creating a pull request on this repo:
https://github.com/transformerlab/galleries
How a Plugin is Found and Run
Installing a Script
When a plugin is installed, its contained setup.sh is run and this setup script may install dependencies.
Plugin Types
Inside the plugin index.json there should be a field called "type" which defines what type of plugin it is. Valid options for type include:
- training
- loader
- evaluation
Transformer Lab will request all plugins of a specific type when setting up a plugin in a part of the application.
Running a Script
Once it is time for the application to run a plugin, its main.py is called as a python script using Popen which spins up a new process and runs the plugin.
Passing Parameters to the Script
A script needs information in order to run. For example a script that loads a model for inference will need to know the model name and any implementation-specific inference parameters.
Specifying Parameters
Your script's info.json will specify the parameters it needs.
You can see an example here:
The format of the parameter specification is using the react-jsonschema-form format which is shown here:
https://rjsf-team.github.io/react-jsonschema-form/docs/quickstart
We use this format because then we can dynamically render a form to handle these parameters in a GUI.
Note that there are some custom parameters that will automatically be sent to a script depending on the type of script. For example, all training scripts receive:
- model_name
- dataset_name
- template_name
- formatting_template
So these do not have to be specified in the parameters array, they will be sent regardless.
Getting Parameters
Parameters are passed to scripts using an input file which contains JSON. When the script is called, a commandline parameter called --input-file is sent to the script. The ccommandline parameter called --input-file specifies the path and filename of a file that the script can open and read in as JSON in order to get parameters.
An example of how to find and read the input file is included in the sample-plugin and looks like the following:
parser = argparse.ArgumentParser()
parser.add_argument('--input_file', type=str)
args, unknown = parser.parse_known_args()
with open(args.input_file) as json_file:
input_config = json.load(json_file)
Now the variable input_config will contain all the information that the script needs to run.
Inside input_config is an object that contains configuration data, and the full experiment definition. As an example it may look something like:
{
"experiment": {
"id": 1,
"name": "alpha",
"config": {
"foundation": "lmsys/vicuna-7b-v1.5",
"adaptor": "",
"prompt_template": {
"system_message": "",
"system_template": "",
"human": "[INST]",
"bot": "[/INST]",
"messages": ""
},
"inferenceParams": {
"8-bit": 0,
"cpu-offload": 0,
"inferenceEngine": 0
},
"foundation_model_architecture": "LlamaForCausalLM",
"plugins": [
"t5_lora_trainer",
"vllm_server",
"llama_trainer",
"llama_cpp_server",
"sample_plugin"
],
"foundation_filename": ""
},
"created_at": "2023-11-16 18: 42: 37",
"updated_at": "2023-11-16 18: 42: 37"
},
"config": {
"template_name": "test",
"plugin_name": "sample_plugin",
"model_name": "lmsys/vicuna-7b-v1.5",
"model_architecture": "LlamaForCausalLM",
"dataset_name": "tatsu-lab/alpaca",
"formatting_template": "Instruction: $instruction \\n###\\n Prompt: $prompt\\n###\\n Generation: $generation",
"adaptor_name": "aa",
"model_max_length": "2048",
"num_train_epochs": "3",
"learning_rate": "1",
"lora_r": "8",
"lora_alpha": "16",
"lora_dropout": "0.1"
}
}