Generating Datasets and Training Models with Transformer Lab

Introduction
In this tutorial, we'll explore how to bridge a knowledge gap in our model by generating custom dataset content and then fine-tuning the model using a LoRA adapter. The process begins with generating data from raw text using the Generate Data from Raw Text Plugin and concludes with fine-tuning via the MLX LoRA Plugin within Transformer Lab.
Step 1: Testing the Model's Base Knowledge
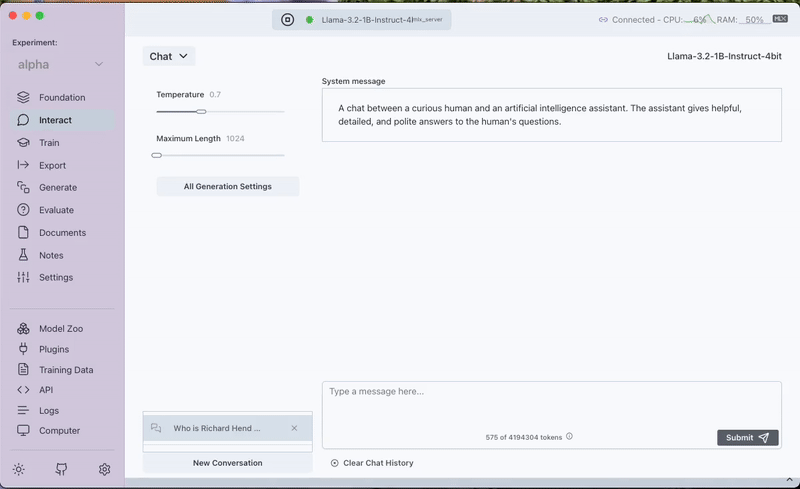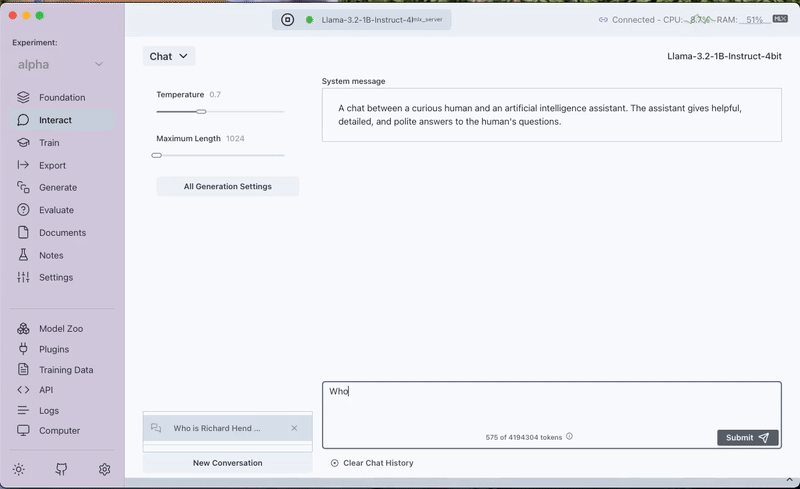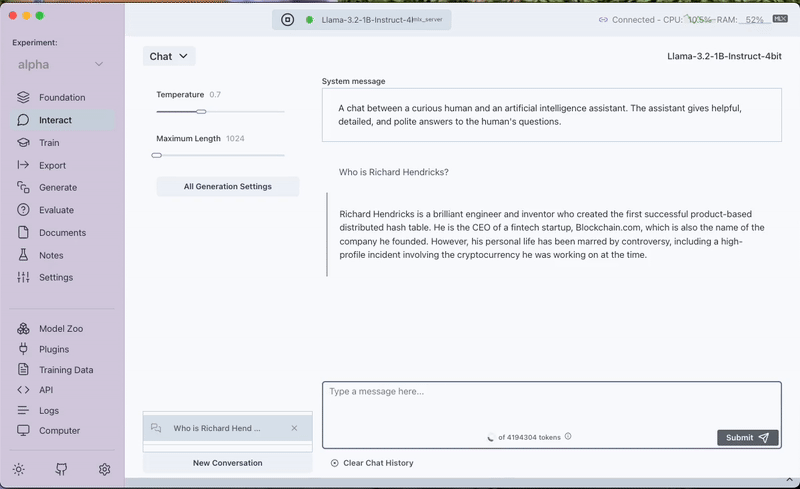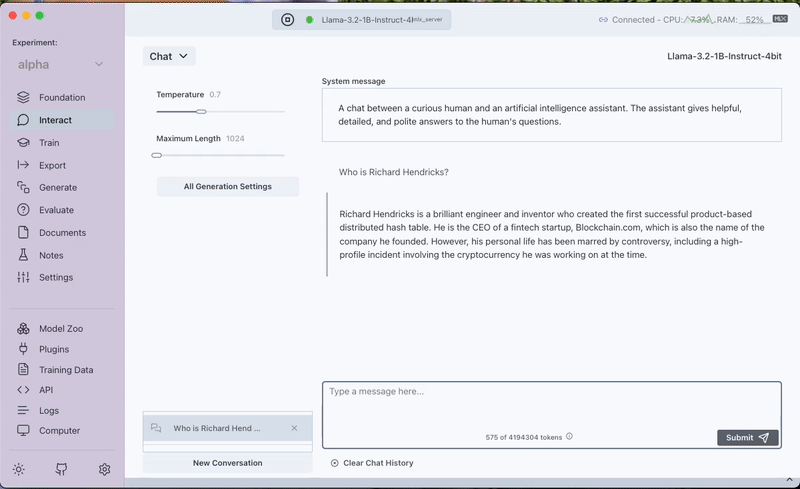
We start by asking our model a question about the character Richard Hendricks from the TV show Silicon Valley. Powered by the mlx-community/Llama-3.2-1B-Instruct-4bit model, it quickly reveals that it has no knowledge of the show or its characters—setting the stage for why fine-tuning is necessary.
Step 2: Generating a Custom Dataset
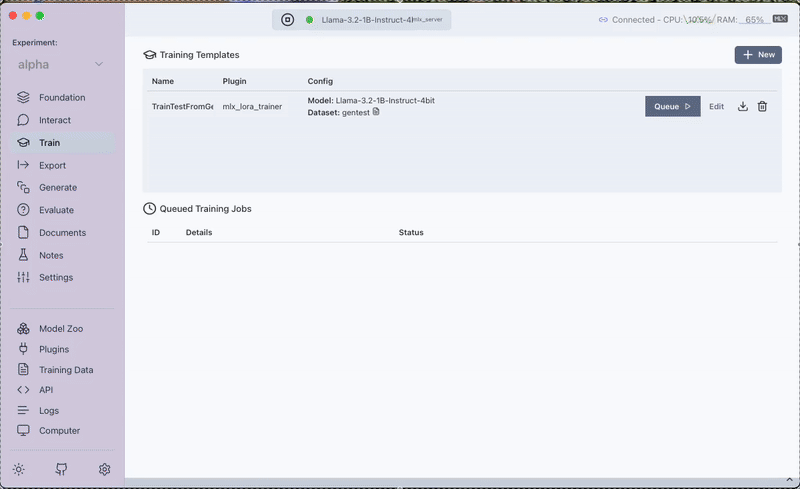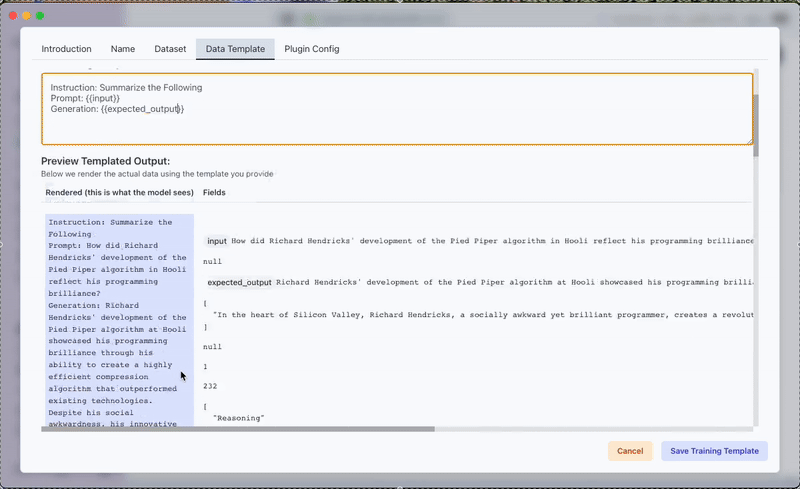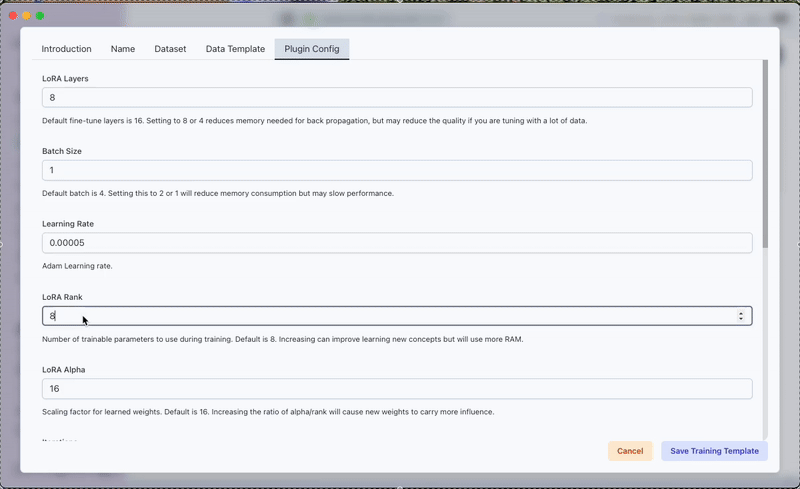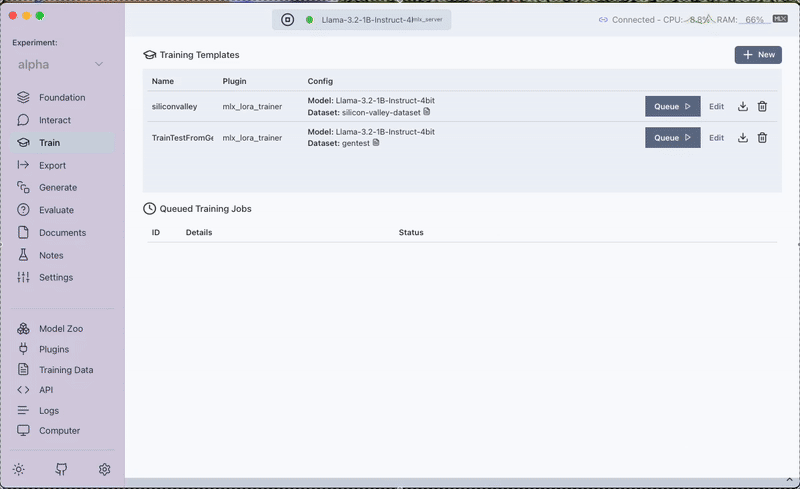
Realizing the model's limitations, we sourced a concise synopsis of the TV show Silicon Valley from the internet. Using this raw text, we generated a small but focused dataset by leveraging the Generate Data from Raw Text Plugin. Here's how:
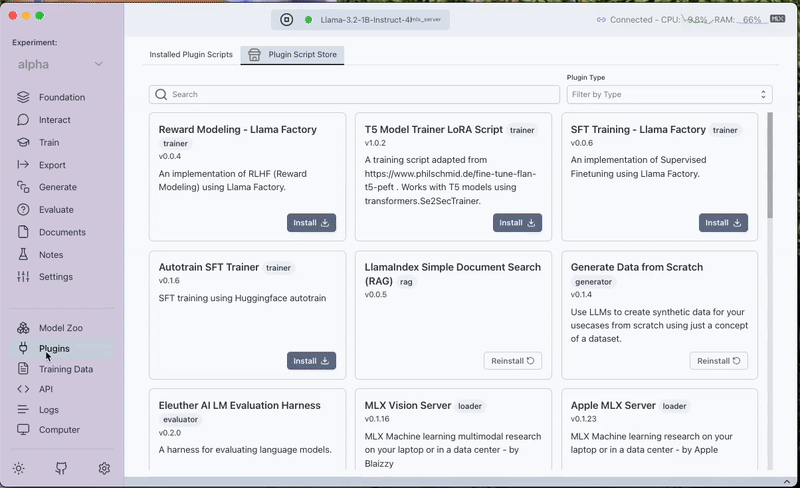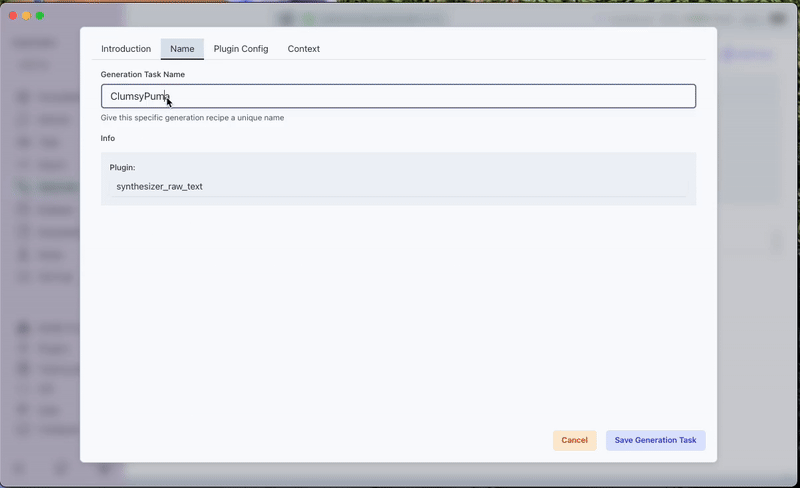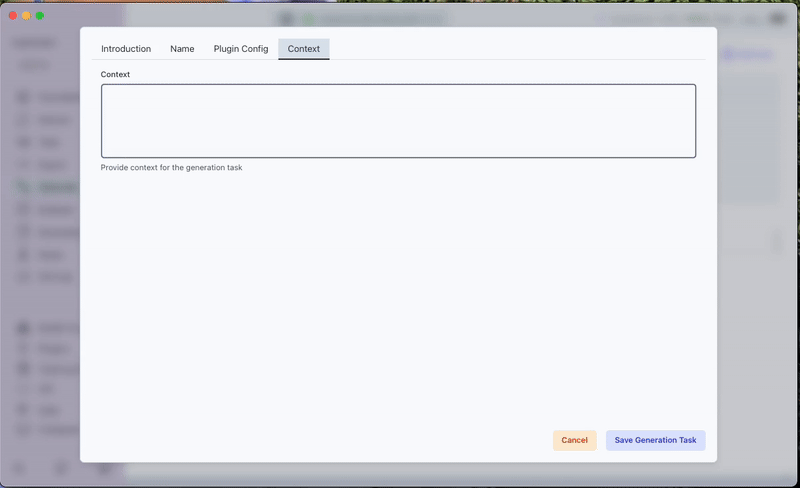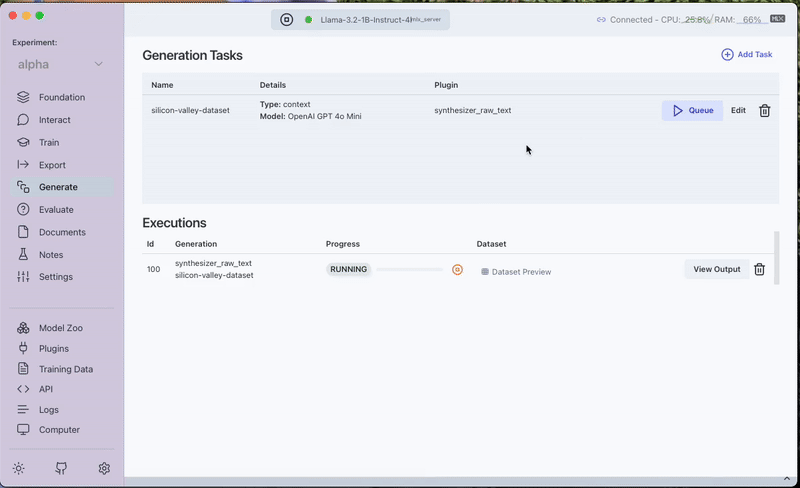
- Download the Plugin:
- Navigate to the Plugins Tab.
- Use the filter by type generator.
- Download the Generate From Raw Text Plugin.
-
Create a Generation Task:
- Switch to the Generator Tab and click Create Task.
- Select Generate from Raw Text from the drop-down menu.
- A configuration window appears.
-
Configure Your Task:
- Name Your Task: Enter a descriptive name.
- Plugin Configuration: Choose a generation model (options include Claude, OpenAI, or local variants) and set the number of samples.
- Entering Context: Paste the Silicon Valley synopsis into the Context tab.
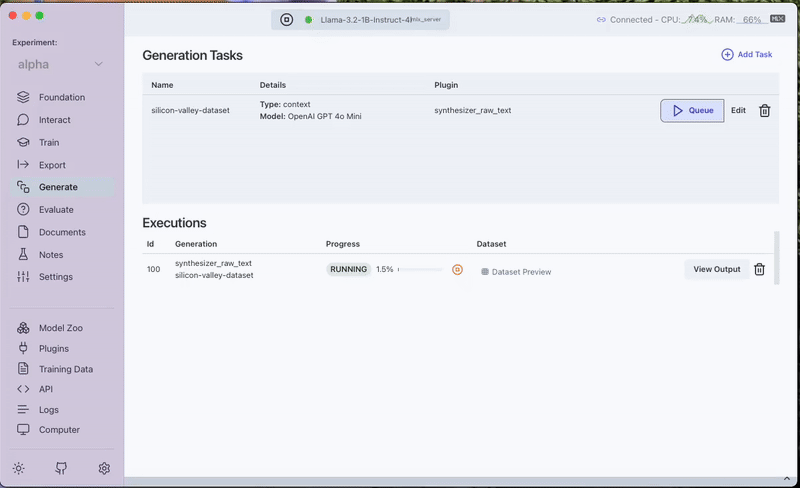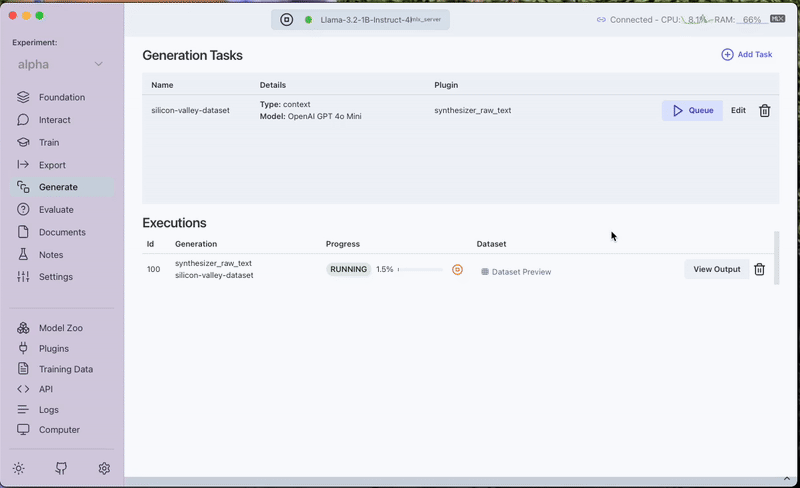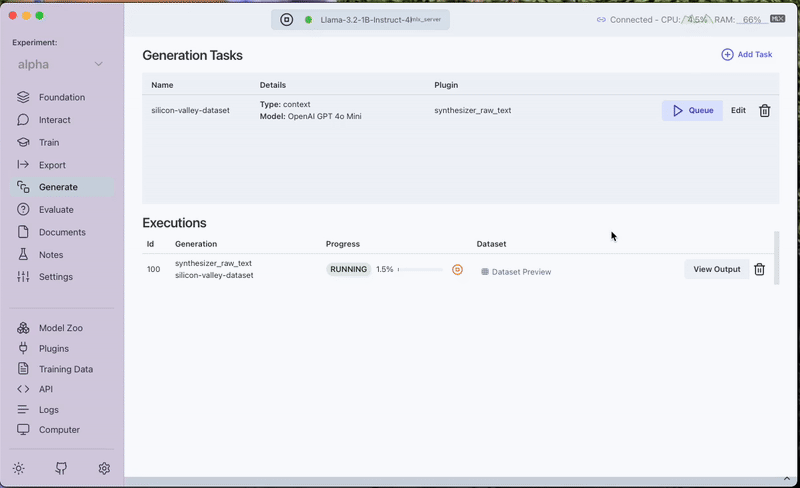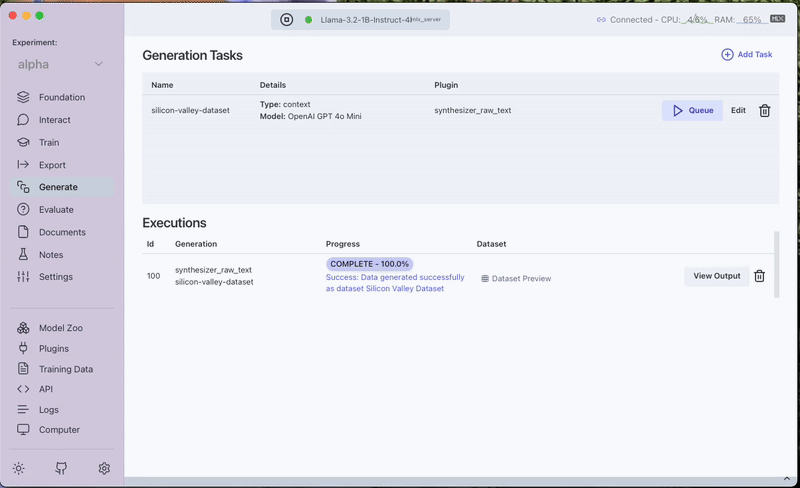
- Run and Preview:
- Save and queue the task.
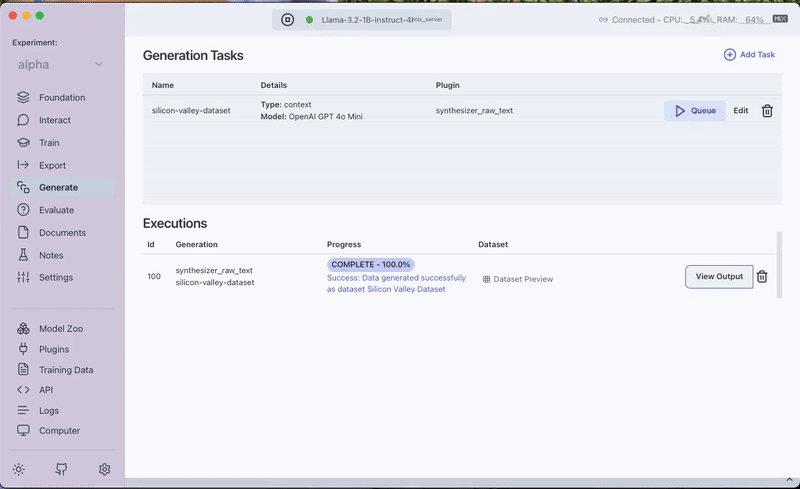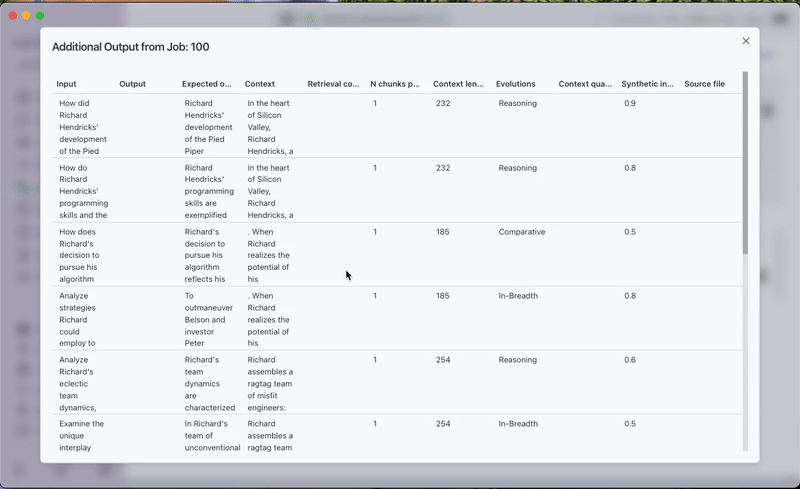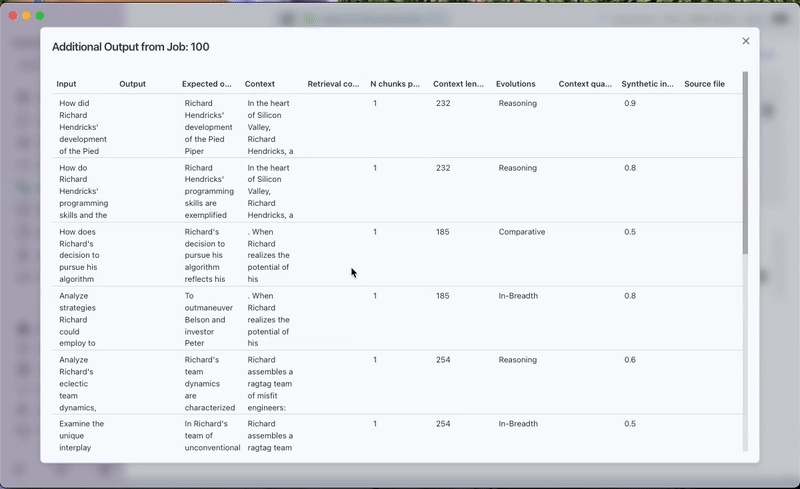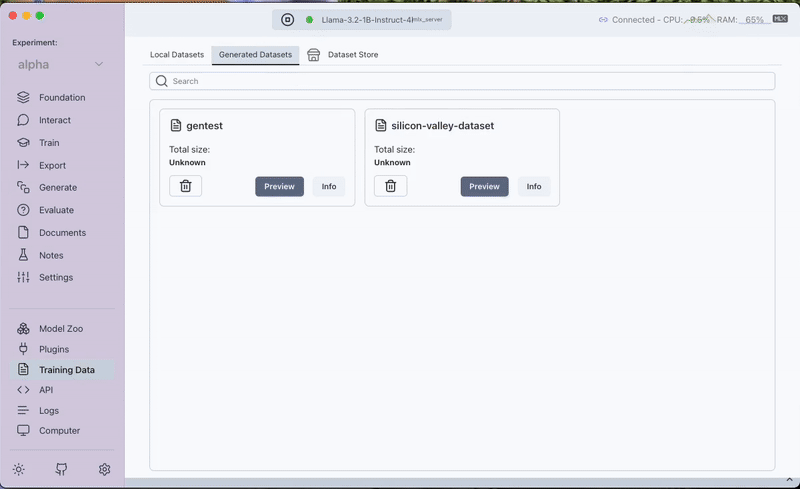
- Once completed, the generated dataset can be previewed under the Generated Tab in the Training Data section.
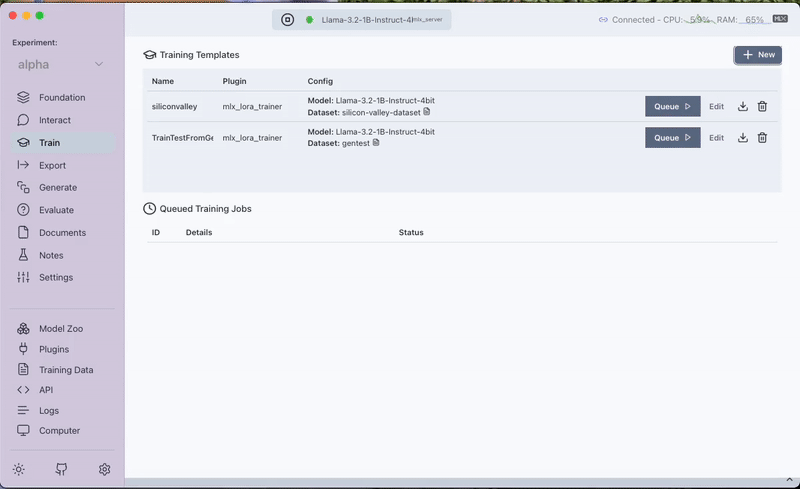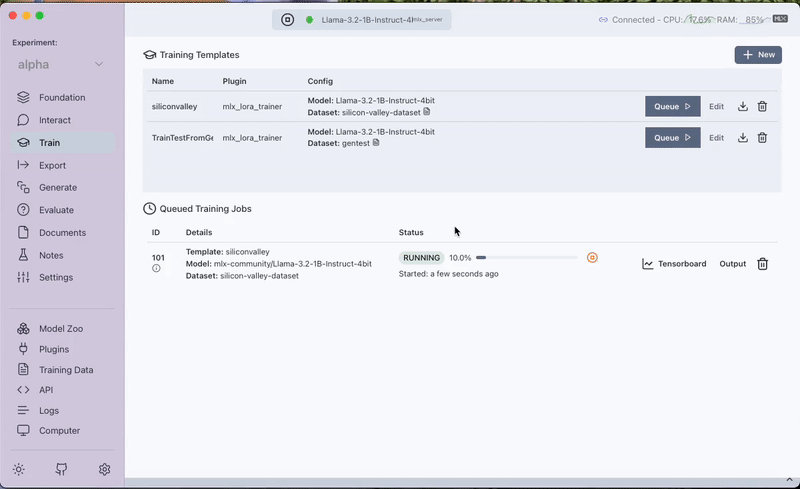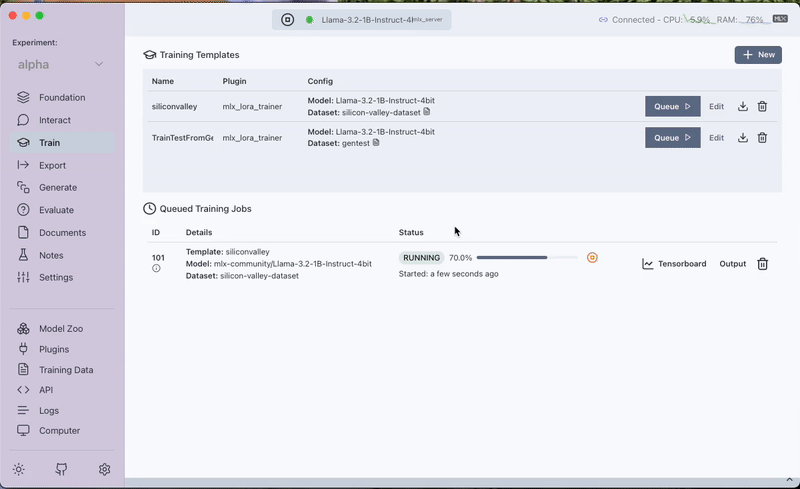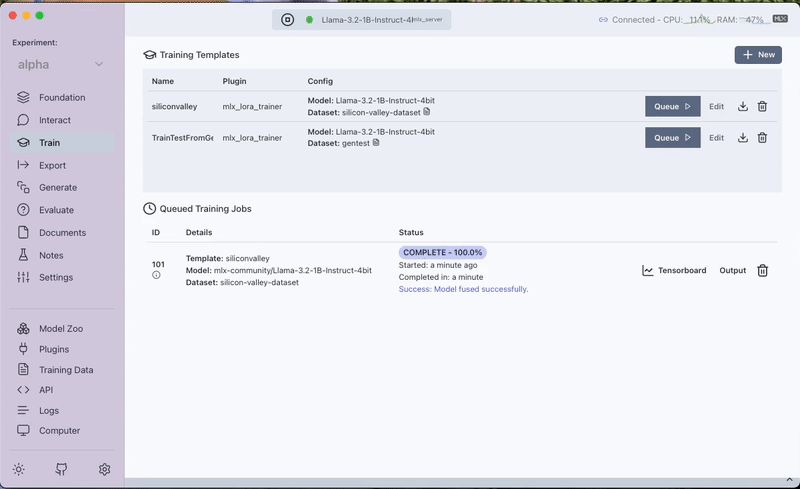
Step 3: Fine-Tuning with the MLX LoRA Plugin
With your dataset ready, the next stage is fine-tuning the model. We utilize the MLX LoRA Plugin in Transformer Lab to train a LoRA adapter on the custom dataset. This process adjusts the model's behavior, empowering it to incorporate the new context provided by the Silicon Valley synopsis.
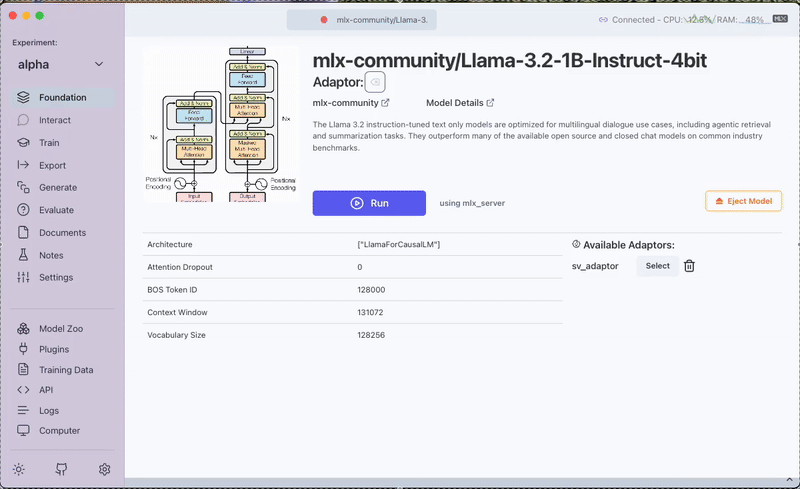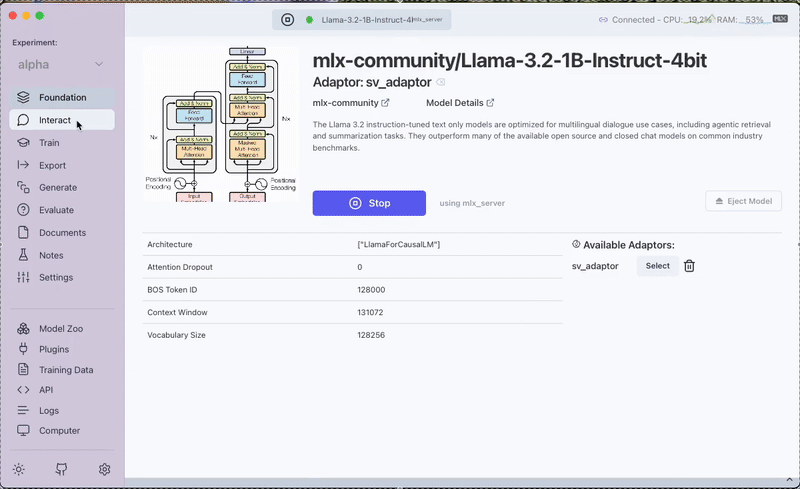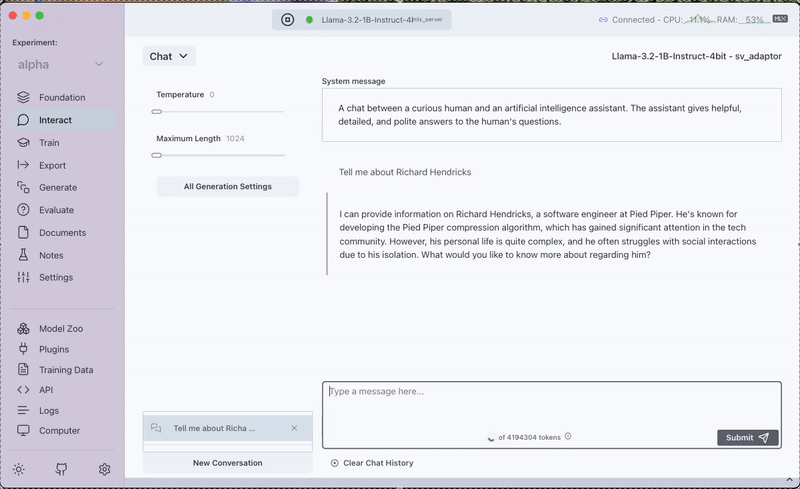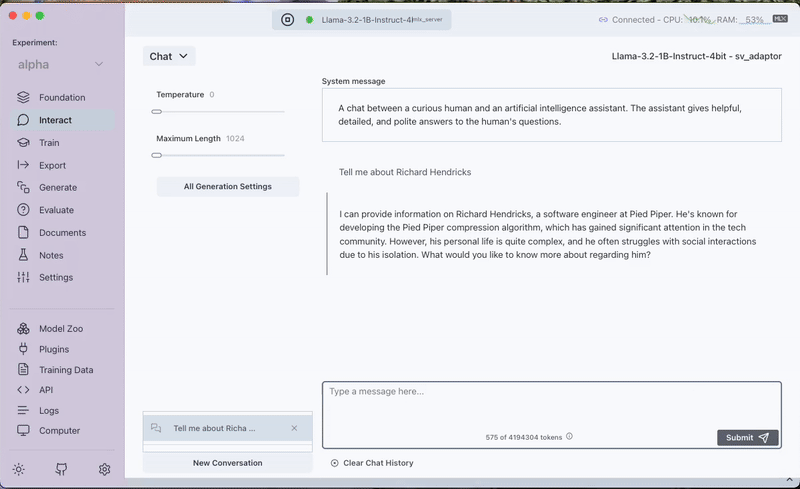
Step 4: Experiencing the Enhanced Model
After fine-tuning, we interact with the model once again. Now, with the LoRA adapter applied, "Richard Hendricks" demonstrates a noticeable improvement in context awareness and relevance. The model’s enhanced responses highlight the benefits of data-driven fine-tuning.
Conclusion
Our new features allow you to easily generate datasets and train models directly from raw text. Simply follow our streamlined workflow: first, use the Generate Data from Raw Text Plugin to create a focused dataset, and then fine-tune your model in just a few clicks with the MLX LoRA Plugin.
This integrated process not only simplifies your workflow but also makes model training more accessible. Whether you're addressing a specific knowledge gap or looking to boost your model's performance, our tools are built to work together seamlessly. By removing the friction between data generation and training, you can focus more on innovation and less on setup.
Stay tuned for more updates as we continue refining our features and techniques!