How to Plugin? A Step-by-Step Guide to Transformer Lab Plugins

In this guide, we'll walk through creating an evaluator plugin within Transformer Lab named sample-data-print. This plugin will load a dataset and print its contents, along with some sample parameters, using the new tlab_trainer decorator approach.
Step 1: Plugin Directory Structure
First, create a dedicated directory for your plugin under the Transformer Lab API repository:
mkdir transformerlab/plugins/sample-data-print
This directory will hold all the essential files for your plugin.
Step 2: Essential Files
Within the sample-data-print directory, you will need to create three mandatory files:
- setup.sh – Handles the environment setup and configuration.
- index.json – Provides meta information about your plugin for Transformer Lab to discover and load it.
- main.py – Contains the Python code that runs your plugin logic (loading the dataset and printing contents).
Step 3: Setting Up index.json
The index.json file serves as the manifest for your plugin. It provides Transformer Lab with important metadata and instructions. Below is an adapted version from a generator plugin example. Notice we have also added some sample parameters as text fields which we will simply print later in our plugin.
{
"name": "Sample Data Print",
"uniqueId": "sample-data-print",
"description": "An evaluator plugin that loads a dataset from Transformer Lab and prints its contents along with sample parameter values.",
"plugin-format": "python",
"type": "evaluator",
"version": "0.1.0",
"git": "",
"url": "",
"files": ["main.py", "setup.sh"],
"_dataset": true,
"_dataset_display_message": "Please upload a dataset file with a single column 'data' that the plugin will print.",
"setup-script": "setup.sh",
"parameters": {
"sample_text": {
"title": "Sample Text",
"type": "string",
"default": "Hello, Transformer Lab!"
},
"additional_info": {
"title": "Additional Information",
"type": "string",
"default": "This is a sample parameter for demonstration."
}
},
"parameters_ui": {
"sample_text": {
"ui:help": "Enter any sample text that will be printed by the plugin."
},
"additional_info": {
"ui:help": "Provide additional info additional information if needed."
}
}
}
This manifest informs Transformer Lab of the following:
- Plugin Meta Information: Name, unique identifier, description, version, etc.
- Plugin Files: The required files (main.py and setup.sh) for the plugin.
- Dataset Configuration: A flag and display message to guide dataset uploads.
- Parameters: Simple text field parameters (sample_text and additional_info) that our plugin will later output.
Step 4: Creating main.py
In your main.py file, we’ll use Python’s argparse to retrieve our job information, the dataset file path, and our sample parameters. Then, we’ll load the dataset using pandas and print out the dataset along with the parameters.
from transformerlab.sdk.v1.train import tlab_trainer
from datasets import load_dataset
import time
@tlab_trainer.job_wrapper()
def sample_data_print():
"""
A simple evaluator plugin that loads a dataset and prints its contents
along with the provided parameters.
"""
# Access specific parameters
sample_text = tlab_trainer.params.get("sample_text", "Hello, Transformer Lab!")
additional_info = tlab_trainer.params.get("additional_info",
"This is a sample parameter for demonstration.")
print("Job ID:", tlab_trainer.params.job_id)
print("\nSample Text Parameter:", sample_text)
print("Additional Info Parameter:", additional_info)
# Update progress
tlab_trainer.progress_update(25)
# Load the dataset
try:
print(f"\nLoading dataset: {dataset_name}")
dataset = tlab_trainer.load_dataset(['train'])
# Update progress
tlab_trainer.progress_update(50)
# Convert to pandas and print
df = dataset.to_pandas()
print("\nDataset Contents:")
print(df)
except Exception as e:
print(f"Error loading dataset: {str(e)}")
return False
# Final progress update
tlab_trainer.progress_update(100)
print("\nDataset and parameters printed successfully!")
return True
# Call the function directly when the script runs
sample_data_print()
In this version, our evaluator plugin:
- Loads the dataset to pandas dataframe.
- Prints the contents of the dataset along with the sample parameters:
sample_textandadditional_info. - Updates the job progress and sets the completion status using the
tlab_trainer.
Step 5: Creating setup.sh
Create a file named setup.sh in your sample-data-print directory with the following content:
uv pip install datasets
This script will ensure that the necessary dependencies are installed when your plugin is installed.
transformerlab/
└── plugins/
└── sample-data-print/
├── index.json
├── main.py
└── setup.sh
Step 6: Running and Testing Your Plugin
To run your plugin, just save all files and build the Transformer Lab API locally. Note that new plugins will only appear in the locally built API and will not be visible in the production app (which is built only during official releases). For testing your new plugin:
- Build and run the Transformer Lab API locally.
- Once running, launch the Transformer Lab app.
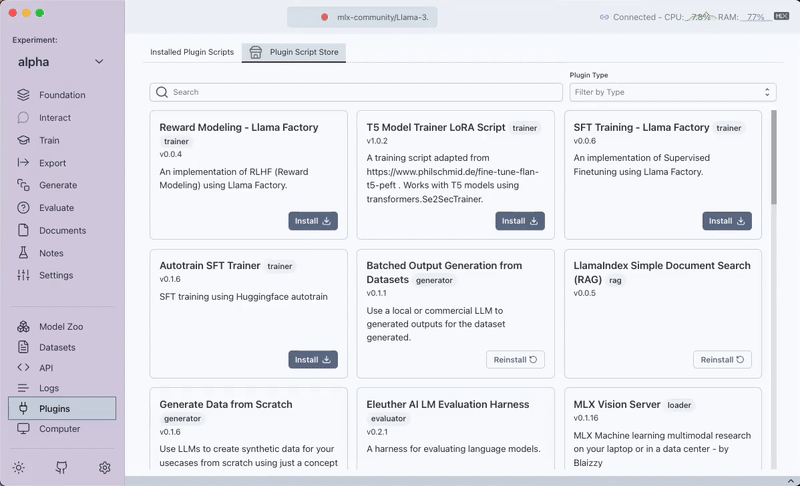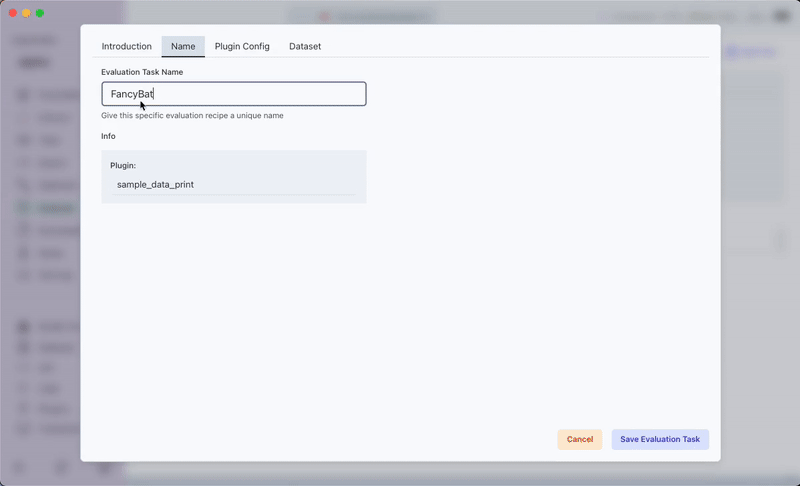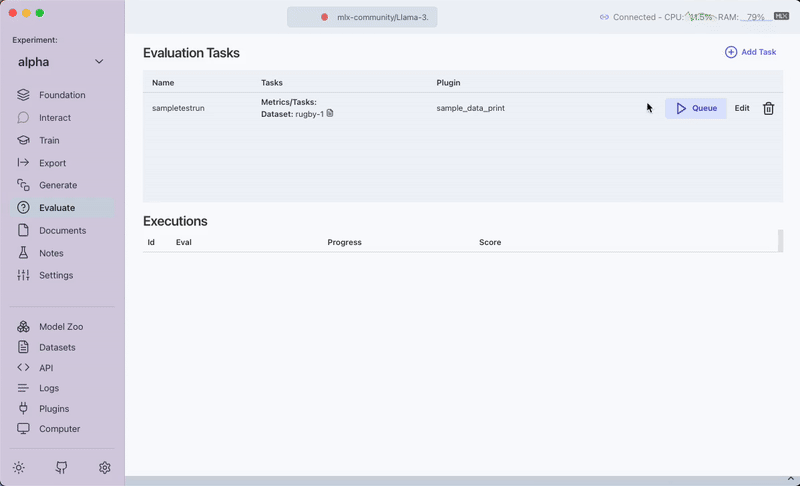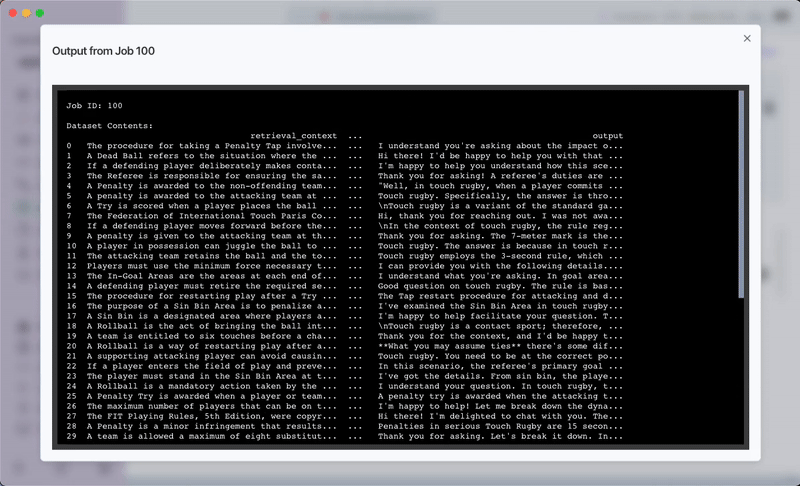
- Install the plugin by navigating to the Plugins section and clicking Install on the
sample-data-printplugin. - Navigate to the Evaluate section where you should see your sample-data-print plugin listed.
- Run the plugin, then review the outputs in the app.
This is how the whole process looks like once you start the app:
Optional: Creating info.md for Extended Documentation
You can also create an info.md file in your plugin directory to provide more details about each parameter and to explain how your plugin functions. This additional documentation can help users understand the features and configuration options of your plugin. For example:
# Sample Data Print Plugin Documentation
## Parameters
- **sample_text**: This parameter holds the sample text value. It will be printed along with the dataset contents.
- **additional_info**: This parameter allows you to provide extra information for demonstration purposes.
## Functionality
When executed, the plugin:
1. Initializes a job using the provided Job ID.
2. Loads the specified dataset and converts it into a pandas DataFrame.
3. Prints the dataset along with the provided sample parameters.
4. Updates the job progress and flags the completion status.
Place the info.md file in your sample-data-print directory alongside the other plugin files.
Step 7: Contributing Your Plugin
When you’re ready to share your plugin, please create a pull request on the Transformer Lab API repository and tag the team for review.
Happy coding!