Auto-Caption Images with WD14 Tagger (wd14_captioner)
This plugin uses the WD14 tagger (from the kohya-ss/sd-scripts) to automatically generate Danbooru-style tags for image datasets. It is ideal for preparing high-quality captions for datasets used in fine-tuning Stable Diffusion or similar models.
Step 1: Prepare Your Image Dataset
Upload a dataset containing image files. The dataset must include an image column (default: "image"). You can configure the name of this column via the Image Field parameter.
The model supports
.jpg,.jpeg,.png, and.webpformats.
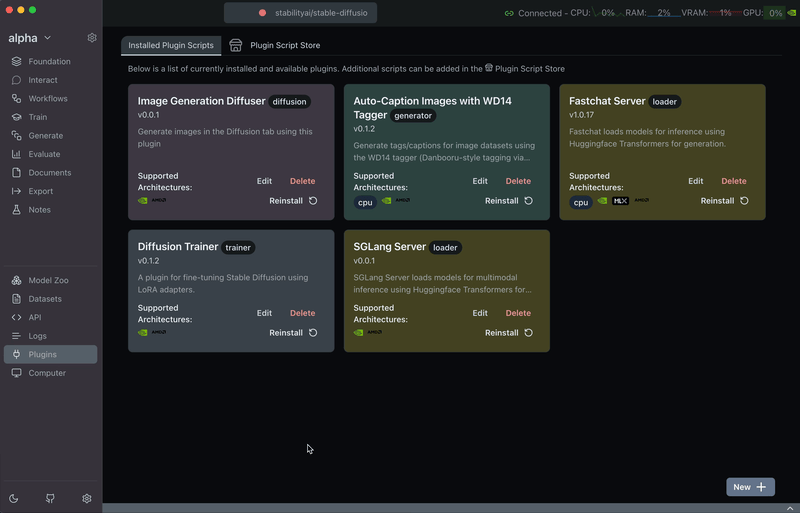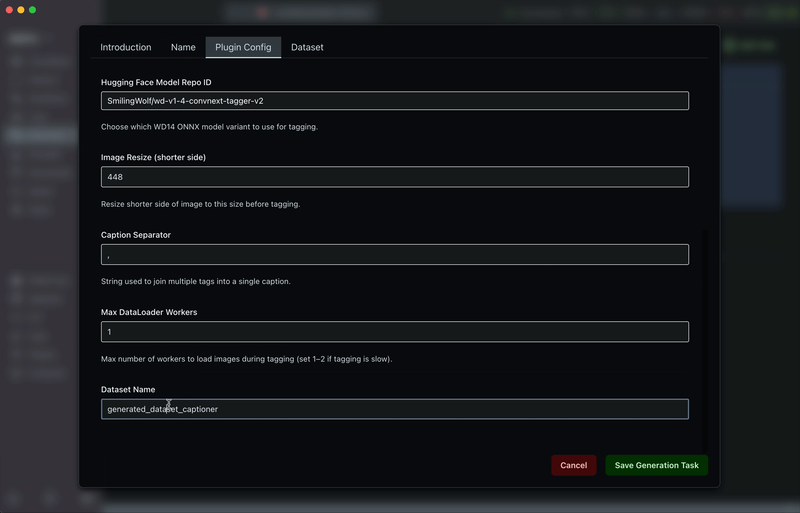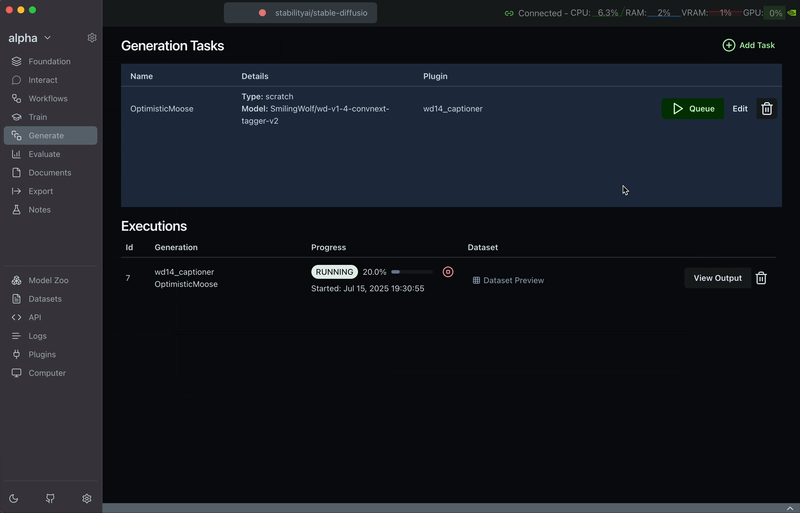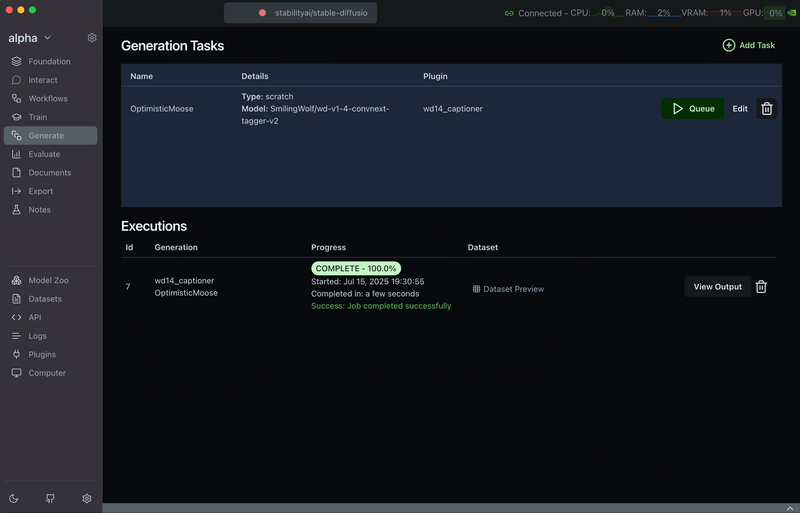
Step 2: Configure Plugin Parameters
Use the parameters panel to control the tag generation behavior:
| Parameter | Description |
|---|---|
Image Field | Dataset column that contains the image files |
Tag Confidence Threshold | Minimum confidence score for a tag to be included |
General Threshold | Optional threshold specifically for general (non-character) tags |
Character Threshold | Optional threshold specifically for character tags |
ONNX Model Variant | Choose between ConvNeXt or ViT variants of WD14 |
Batch Size | Number of images to process at once |
Image Resize | Resize shorter side of image before inference |
Caption Separator | Character(s) used to join multiple tags |
Max Dataloader Workers | Max number of workers to load images during tagging |
Step 3: Start the Job
Once your dataset is uploaded and parameters are configured, click the Queue button to start captioning. You can monitor job progress in the Executions tab.
When executed, the plugin will:
- Load your image dataset
- Run the selected WD14 model on each image
- Generate tags/captions based on your thresholds
- Save the results as a new dataset with two columns:
image(original file path)caption(generated tags)
Step 4: View the Output
After completion, you can view the new dataset inside the Datasets tab under Generated Datasets. The resulting dataset will contain the original images and a new column with generated captions.
You can also edit the captions and create a new dataset for downstream tasks like training, search, or labeling.
Output Example
| image | caption |
|---|---|
pokemon_1.png | solo, simple_background, white_background, full_body, black_eyes, pokemon_(creature), no_humans, animal_focus |
pokemon_2.jpg | solo, smile, open_mouth, simple_background, red_eyes, white_background, standing, full_body, pokemon_(creature), no_humans, fangs, bright_pupils, claws, white_pupils, bulbasaur |
Model Variants
wd-v1-4-convnext-tagger-v2.onnx: More accurate, but largerwd-v1-4-vit-tagger-v2.onnx: Lightweight alternative
These models will be automatically downloaded and cached if not already present.