Using a Local LLM for AutoComplete
· 9 min read

Why Autocomplete
Let's add an LLM to our application!
But what is the best first LLM project to try adding to your production application?
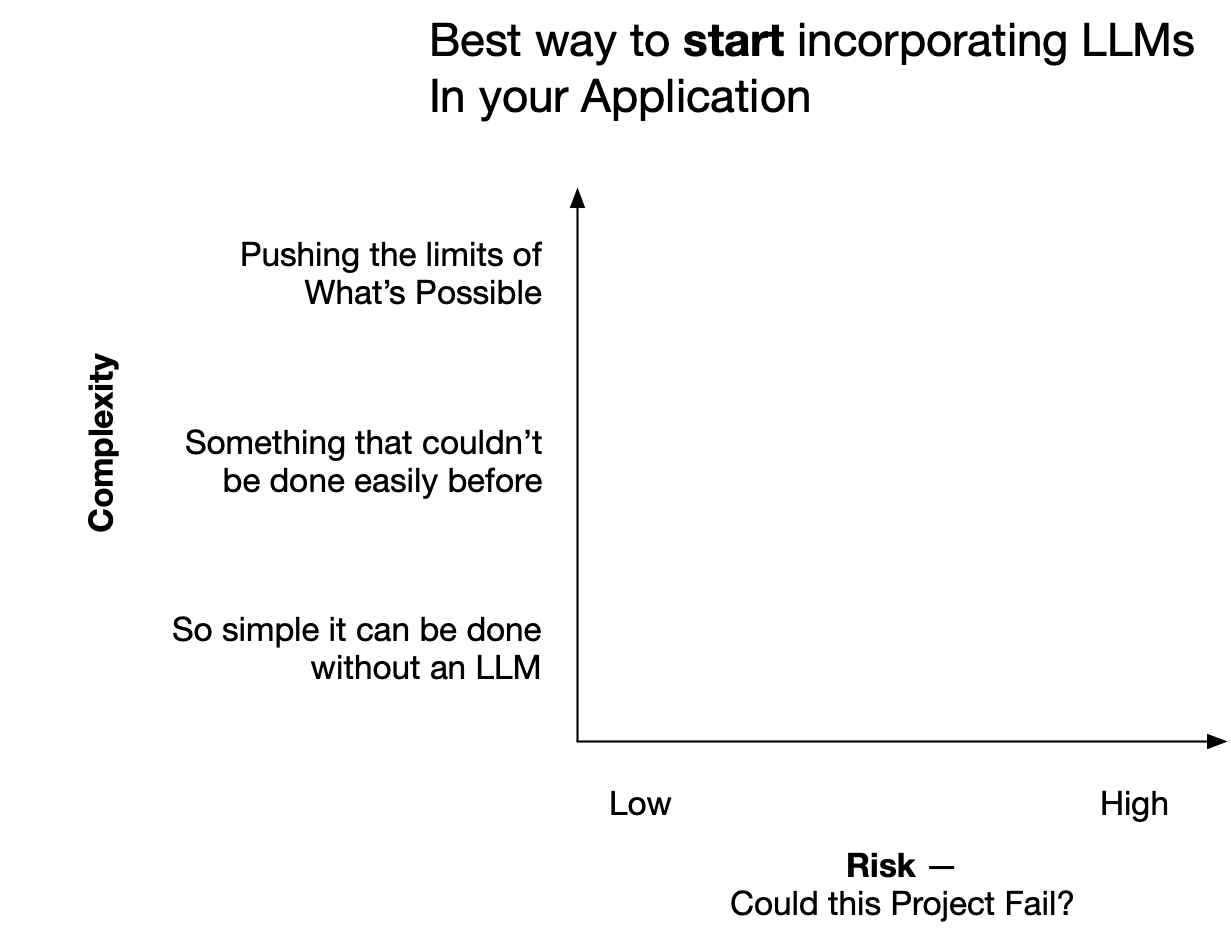
When teams brainstorm LLM opportunities in their product products, there is a tendency to focus on overly complex ideas -- but these ideas often come with high risk.
Autocomplete is a great initial application to current applications because it is well defined (LLMs are well suited for autocomplete), and is relatively simple to implement. It's also something LLMs are particularly well suited towards.
In this post we will set up a system to add autocomplete to an existing product, and then we will suggest future opportunities to improve it.