MLX Exporter Plugin
MLX is an array framework built for efficient model execution on Apple silicon. It leverages the unified memory architecture and a familiar NumPy-like API, along with high-level neural net and optimization tools, to deliver fast model performance. Learn more about MLX
The MLX Exporter Plugin allows you to export your model to the MLX format with quantization. The exported models would only currently work with the Apple M-Series Silicon Chips. Follow the steps below to use the plugin.
Steps to Export
-
Download the Plugin:
Navigate to the Plugins tab and download the MLX Exporter Plugin. -
Switch to the Export Tab:
After downloading, go to the Export tab. -
Select MLX Exporter:
Choose MLX Exporter from the available export options. -
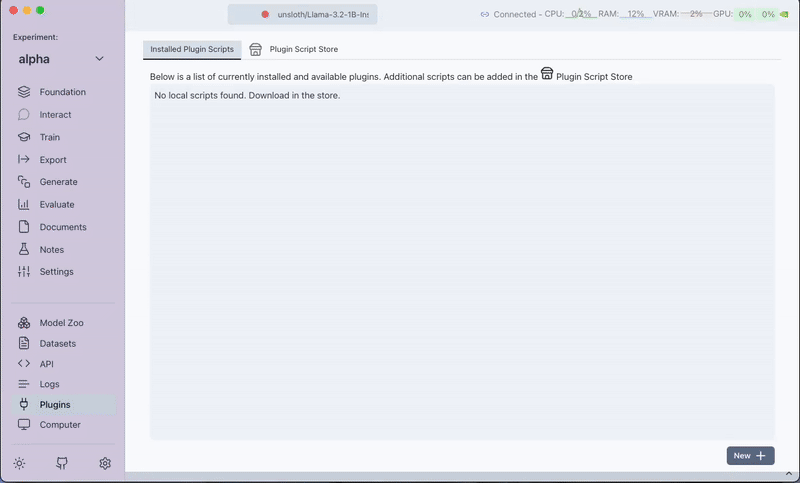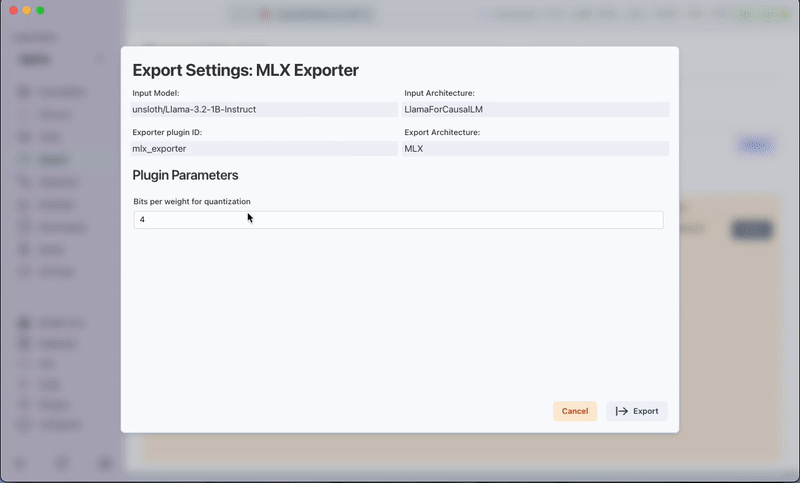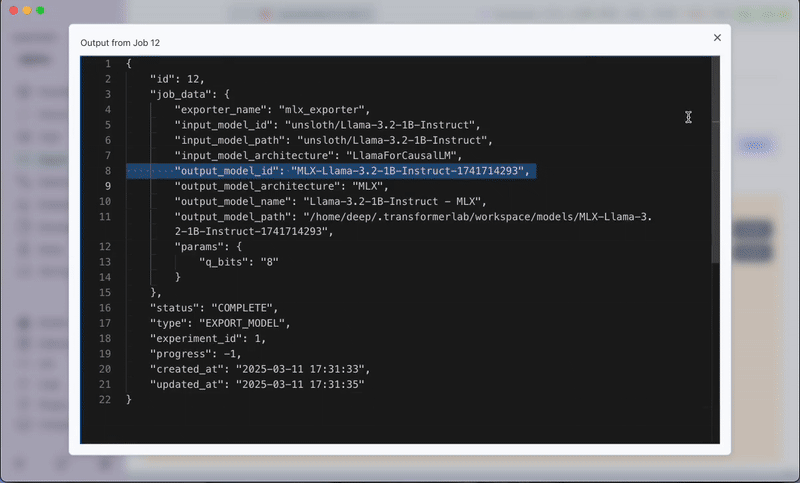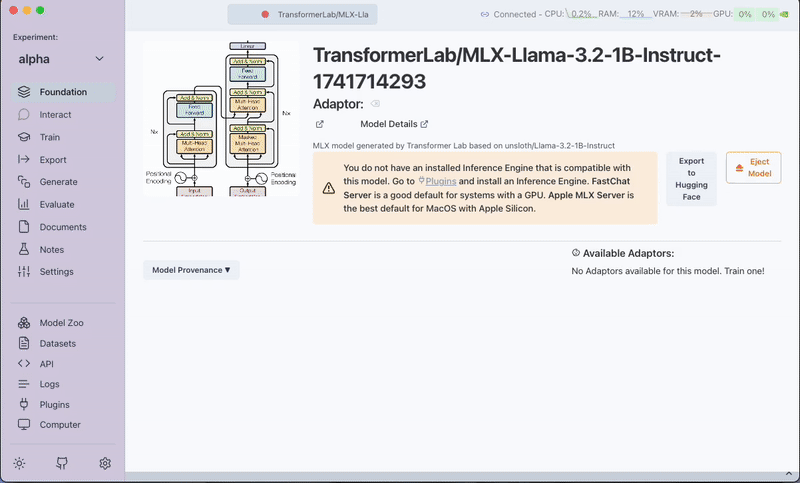
Configure Export Settings:
- Bits per Weight: Enter the bits per weight of quantization. Supported values are 2, 4, or 8.
-
Export the Model:
Click Export. The plugin will process the request and display the exported model in the Foundation tab.
Explore the MLX Exporter Plugin to simplify model quantization and export tasks!
Quantization
Quantization is the process of reducing the precision of the numbers used to represent a model's weights. This helps to decrease memory usage and accelerate inference speed while maintaining a balance with model accuracy.