3. Load and Run a Model
Introduction
An experiment needs a foundation model (LLM).
Open-source LLM's are typicaly very large files (e.g. 3GB or more) that are composed of some configuration files that define the architecture of the LLM they encapsulate as well as a large blog of binary data that captures the values of each neuron in the trained neural net.
Transfomer Lab works with many model formats that support a variety of platforms and engines, and it provides a gallery of common models that serve as a starting point for your experiment. You can also import models from the thousands hosted on Hugging Face, or from your server's file system. For more information, see the section on Importing Models.
Once you have downloaded some local models, you can run them for inference. Behind the scenes, Transformer Lab uses the FastChat library to run models, allowing you to chat or perform completions with them.
Downloading from the Model Store
To start, go to the Model Gallery by clicking on the Model Zoo icon then click on the Model Store tab. Here you can select from many common public models. Once you have selected one, click on and wait for the model to fully download onto your server.
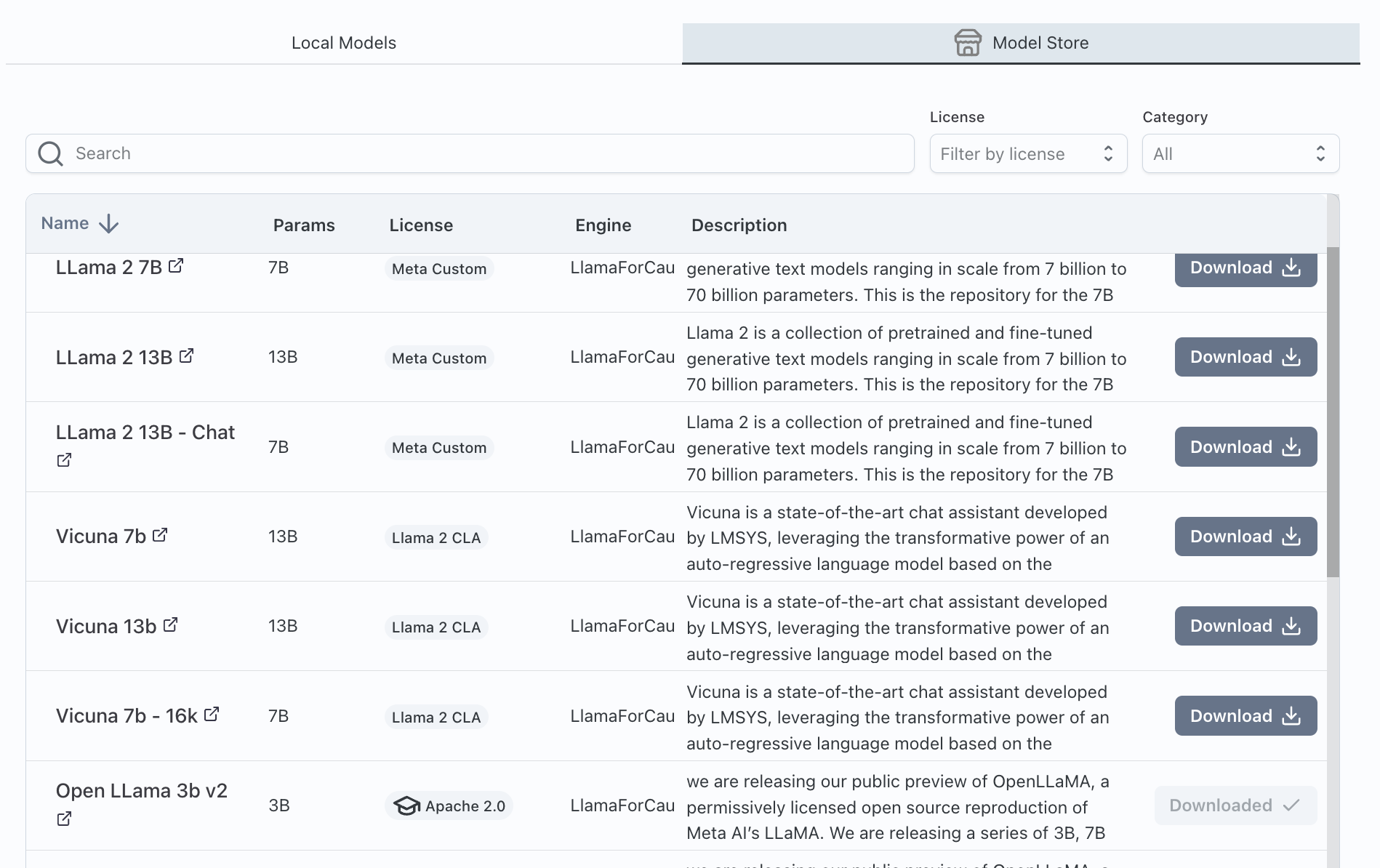
Downloading a model can take several minutes.
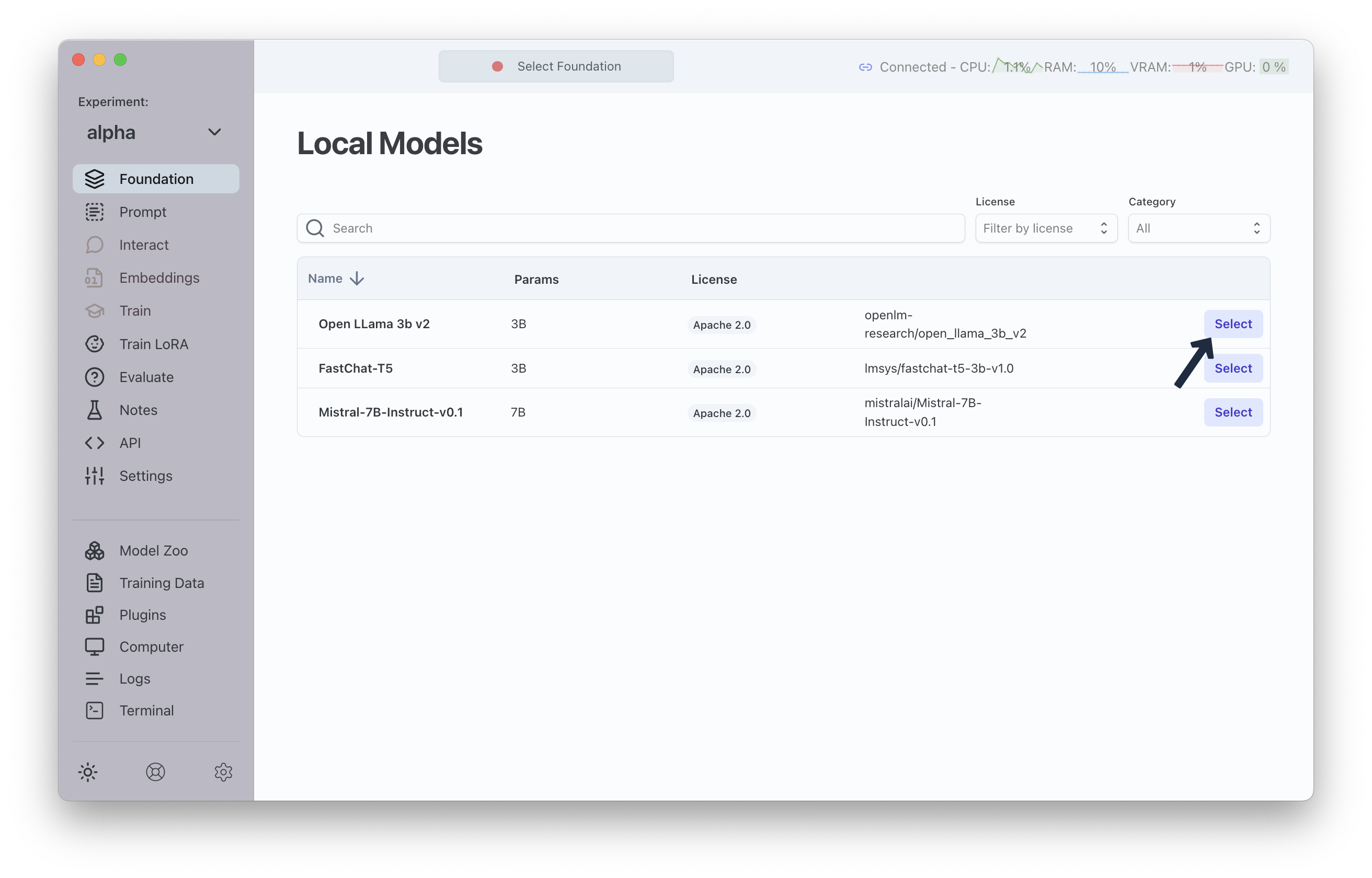
Assigning a Model to an Experiment
Once you have downloaded one or more models from the Model Store they appear in the "Local Models" tab. You can now use these as foundation models for experiments.
To do so, select the current experiment and click on Foundation. If no model has been assigned to the current experiment, you will see a list of local foundation models you can assign to the current experiment.
Once a model is selected, the screen will show the details of the current foundation model like in the following screenshot.
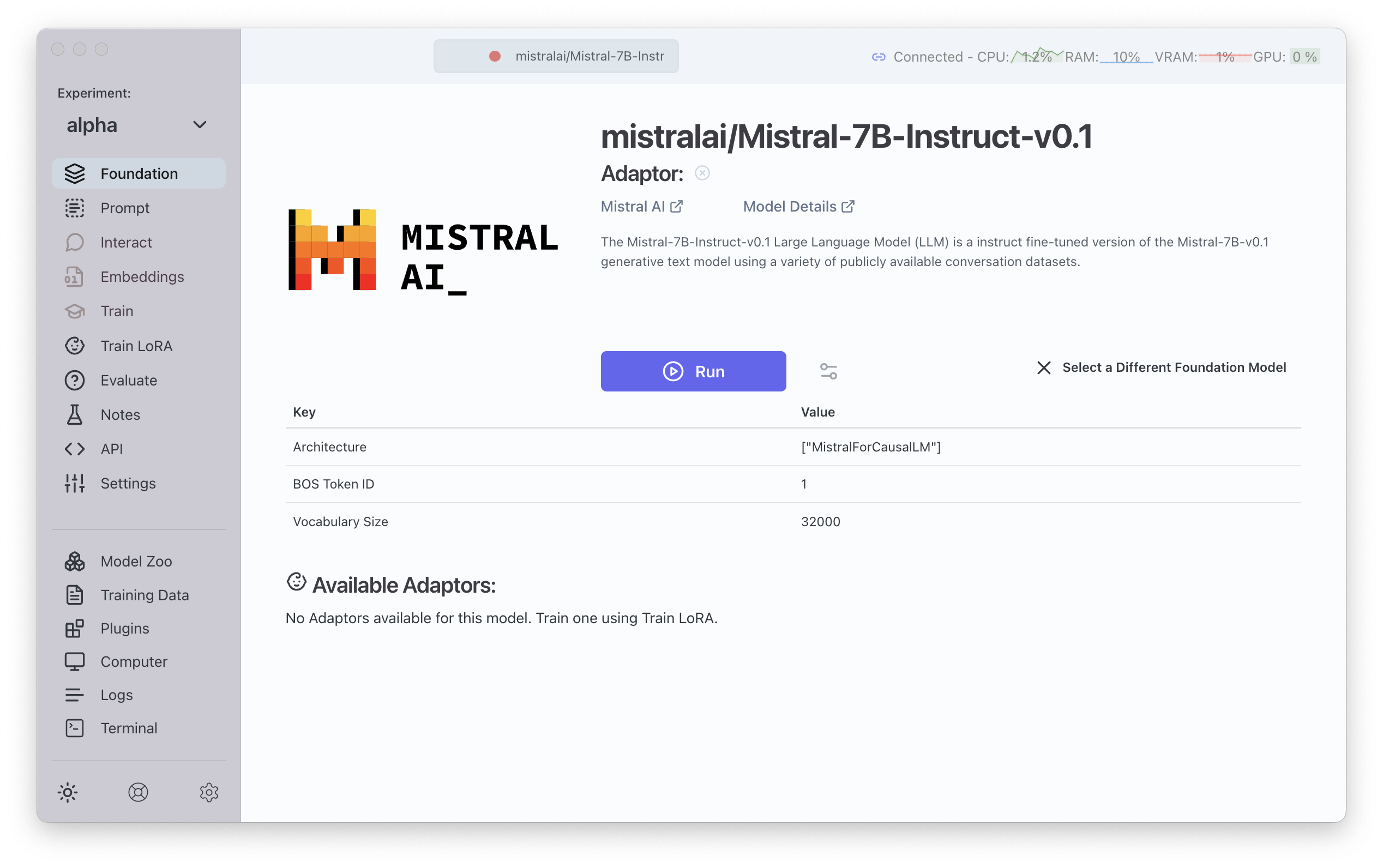
To select a different model, click on Eject Model
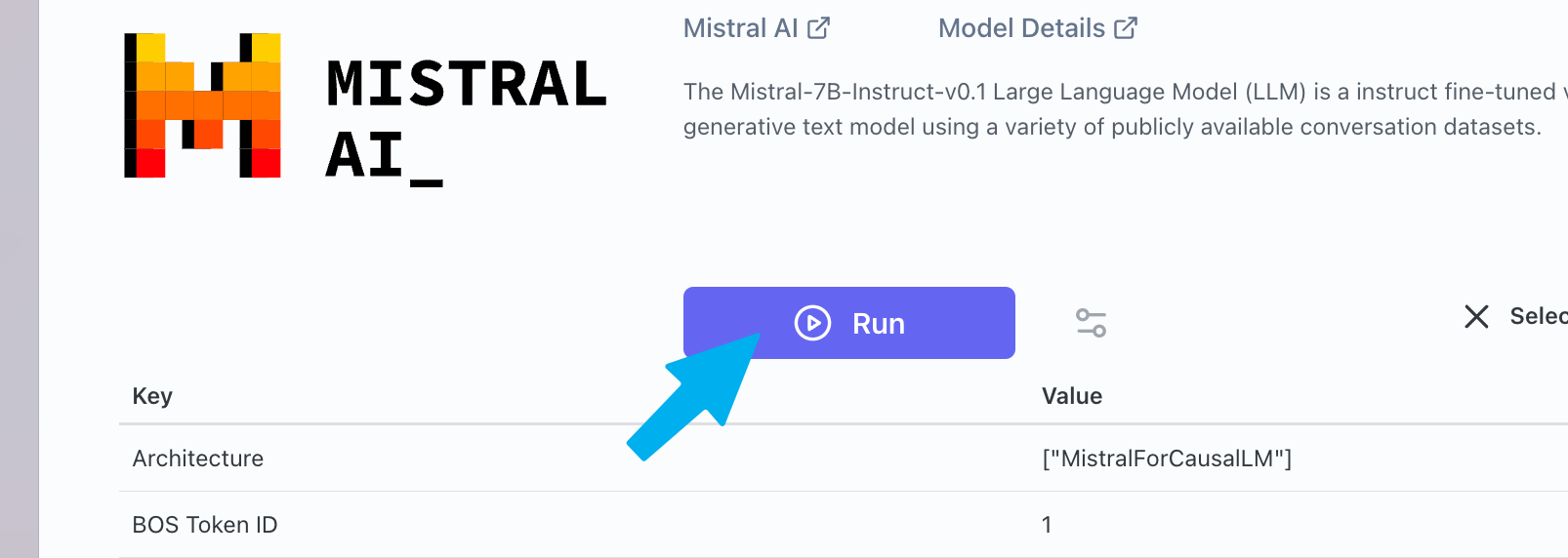
Running a Model for Inference
When you are ready to run your model, click on the button.
Alternate Inference Engines
An inference engine is the library that is used to run your model. By default, Transformer Lab attempts to run your model using a versatile inference engine made by the team at FastChat https://github.com/lm-sys/FastChat
Depending on the Model Architecture, you can select an alternate inference engine. Alternate inference engines are built as Plugins.
Currently Running LLM Display

Once a model is running you will see it's name in the Currently Running LLM Display at the top of the application. A green dot shows that the model is active. The rest of the top header shows how many resources are occupied while running the model.
Press the button in the header to stop the model and free up resources.