Embeddings and Tokenize
This page introduces two powerful features: Embeddings and Tokenize.
Embeddings
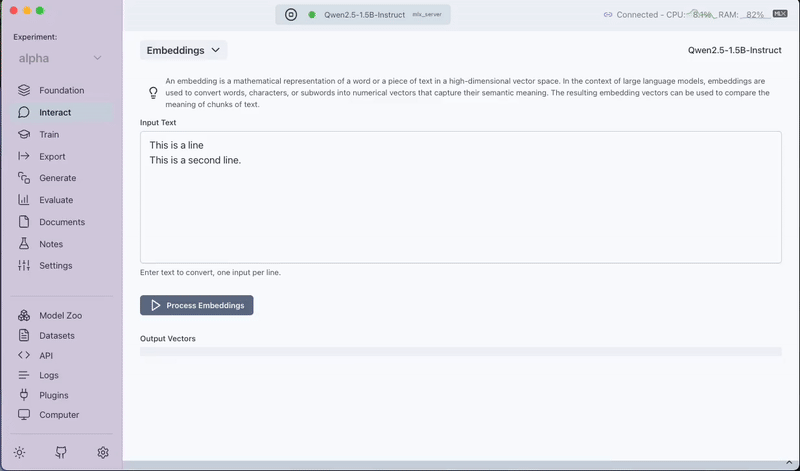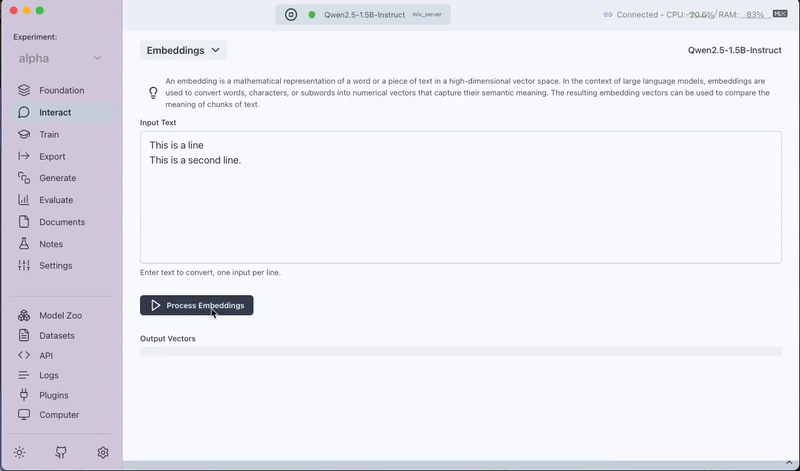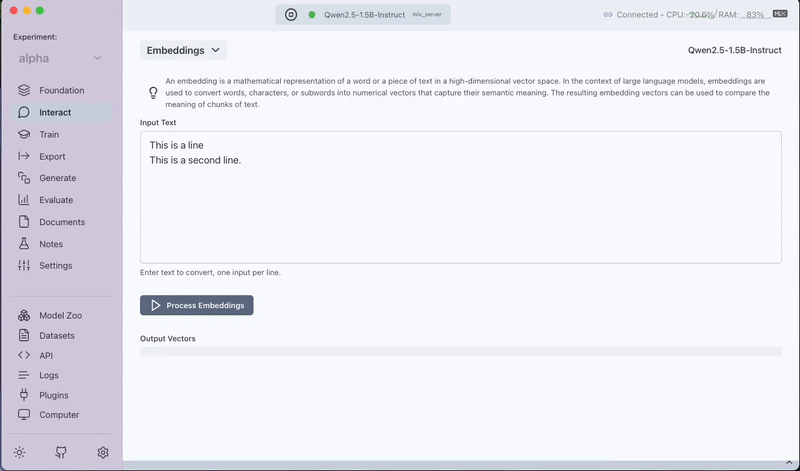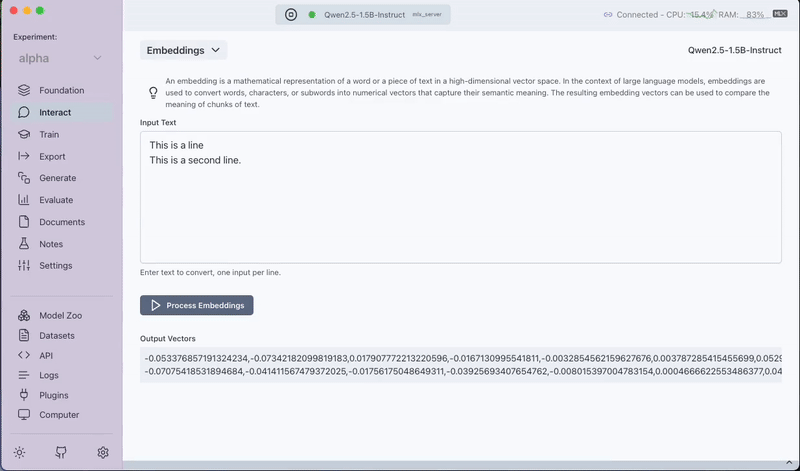
The Embeddings feature allows you to obtain the embedding vectors for any input text. Simply enter your text and the interface will process it to return the corresponding embedding vectors. These vectors represent the semantic meaning of your text in a high-dimensional space, which can be useful for various downstream tasks like similarity search and clustering.
How to Use Embeddings
- Input Text: Enter the text for which you need the embedding.
- Process Embeddings: The system processes the text with the model.
- Output: The output will be a list of vectors representing the input text's embeddings.
Tokenize
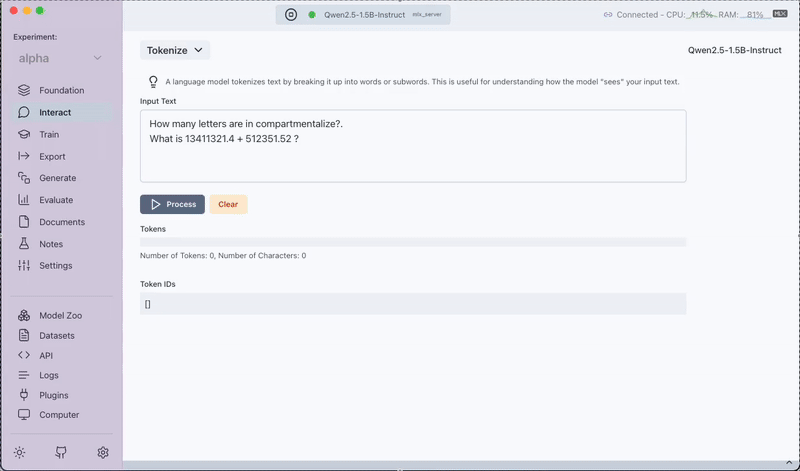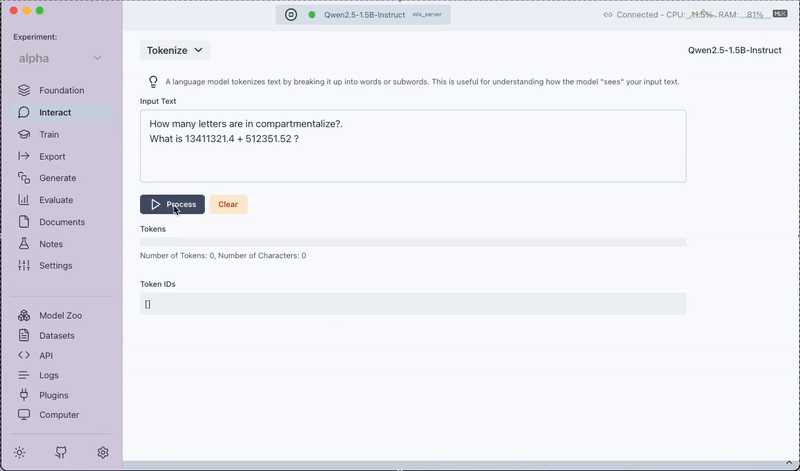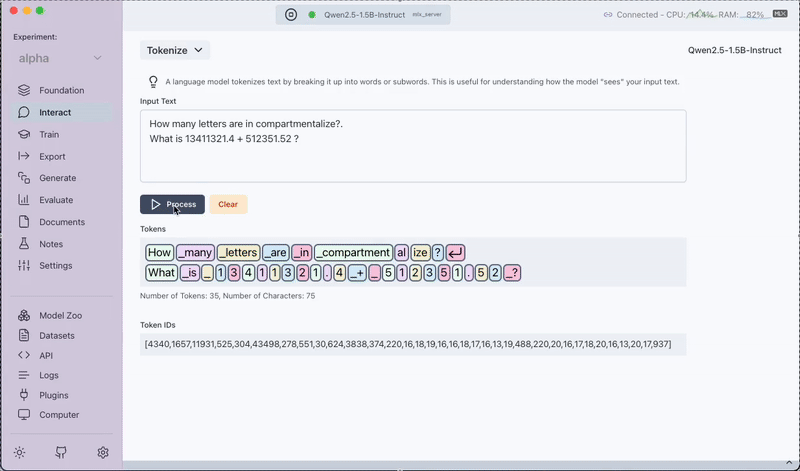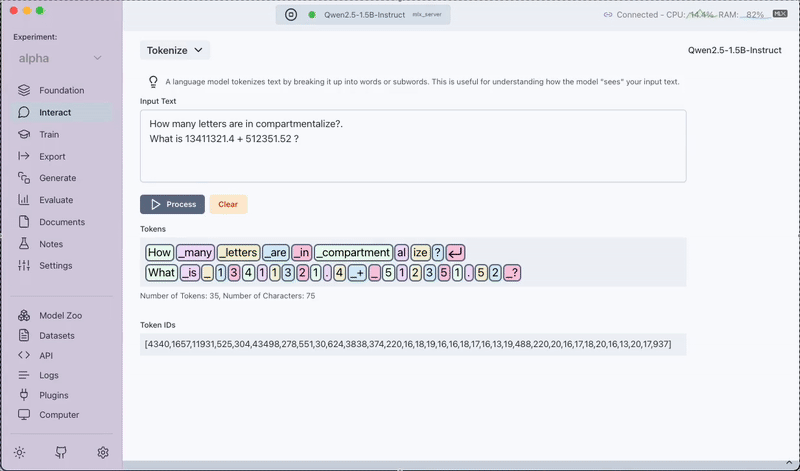
The Tokenize feature provides a visual breakdown of how the model splits sentences into tokens. This includes both words and sub-words as recognized by the model. In addition, you will also receive the corresponding token IDs for each token.
How to Use Tokenize
- Input Sentence: Type in the sentence you want to analyze.
- Process: The sentence is tokenized by the model.
- Output: You will see a visual representation of the tokenization along with the token IDs, helping you understand how the model processes your input.
Explore these features to gain deeper insights into how your text data is being interpreted and transformed by the model!