RAG (Retrieval-Augmented Generation)
RAG enhances large language models by retrieving relevant information from your documents before generating responses. This allows the model to access external knowledge not included in its training data, providing more accurate and context-aware answers.
Setting Up RAG
Step 1: Install the RAG Plugin
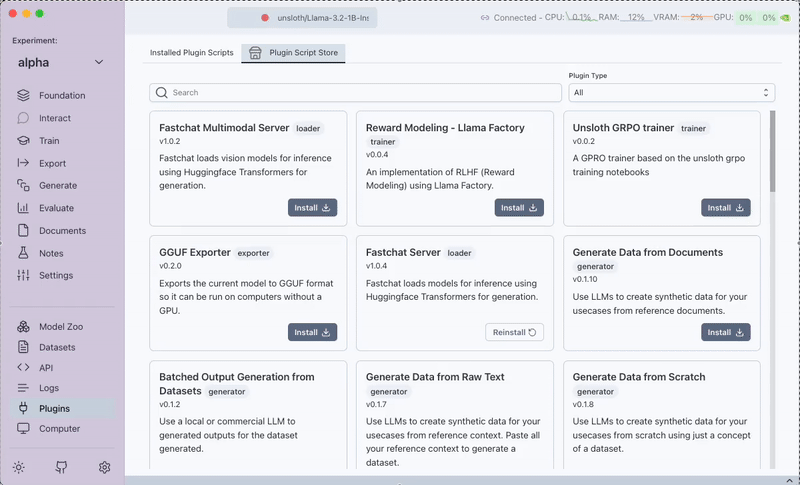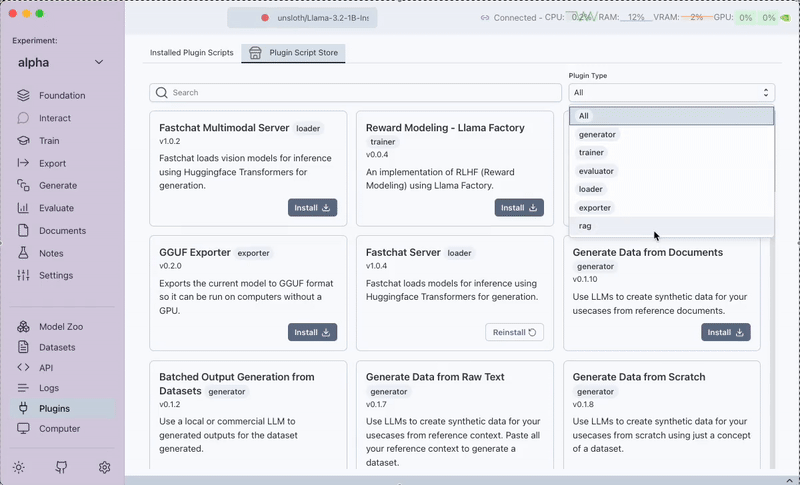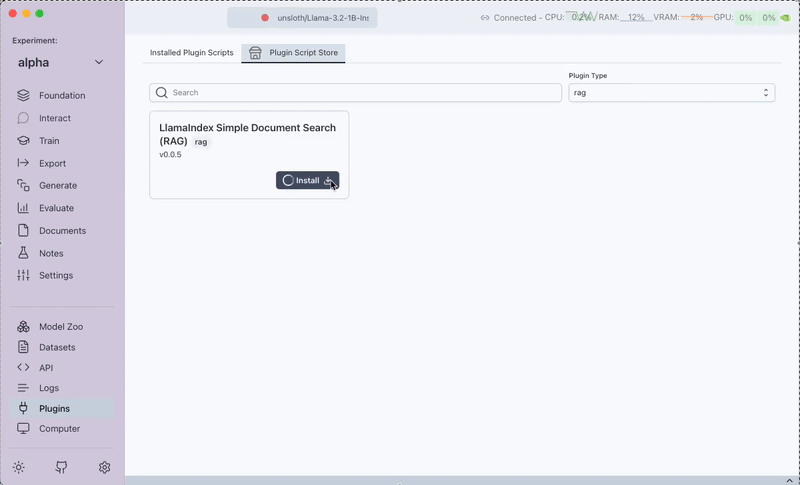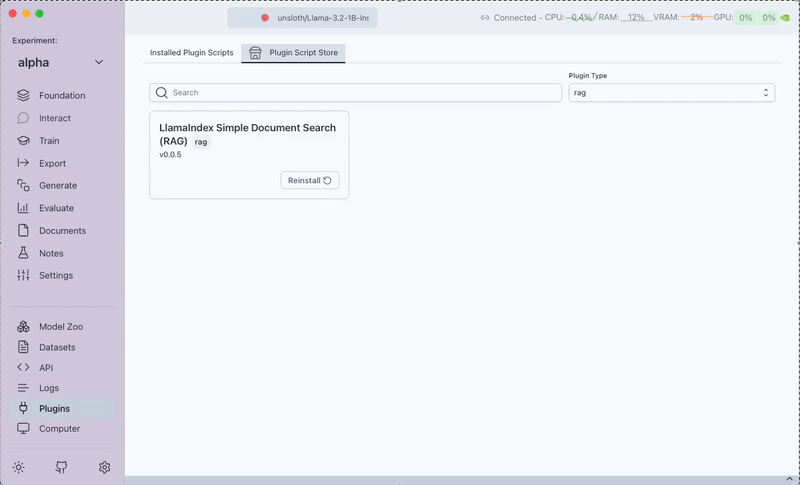
To enable RAG functionality, you first need to install a RAG plugin from the Plugins tab. Currently, Transformer Lab only supports LlamaIndex Simple Document Search (RAG).
Step 2: Run a Foundation Model
After installing the plugin, go to the Foundation tab and run a model you want to use for RAG. Running a model will enable the Interact tab.
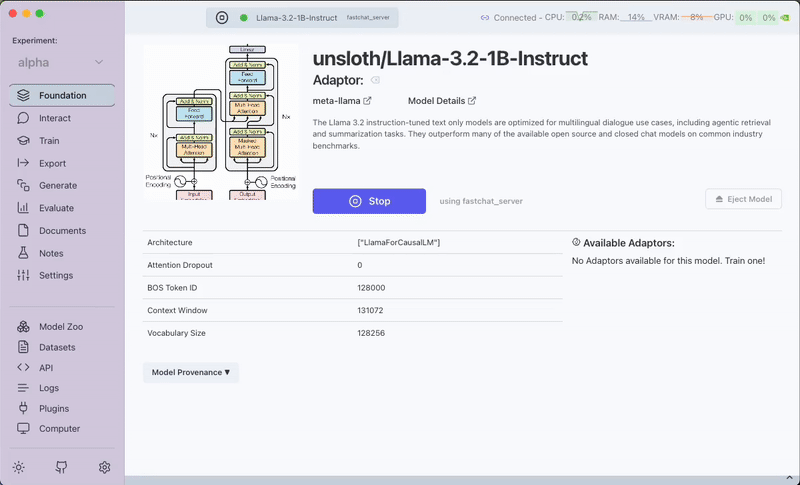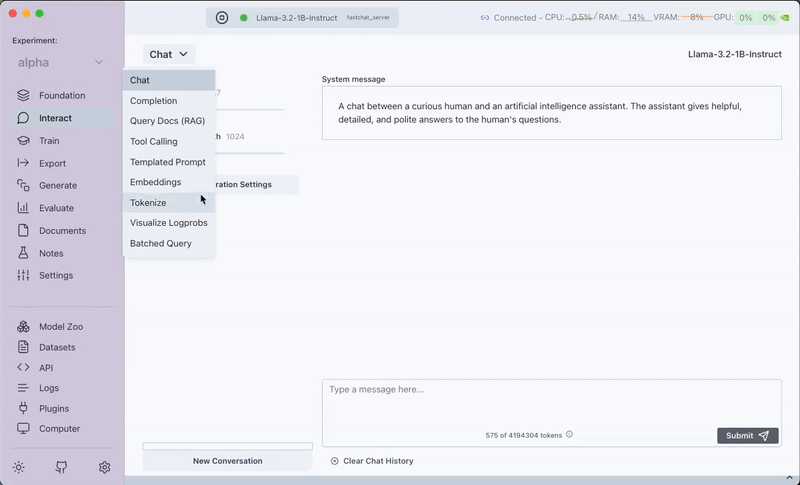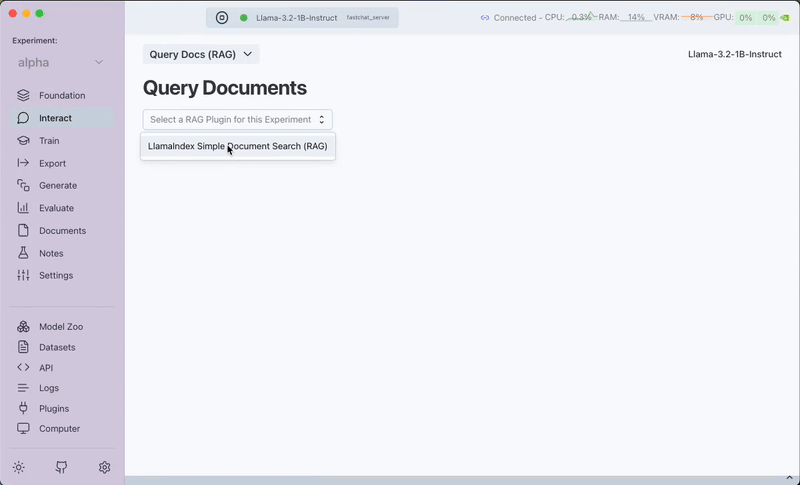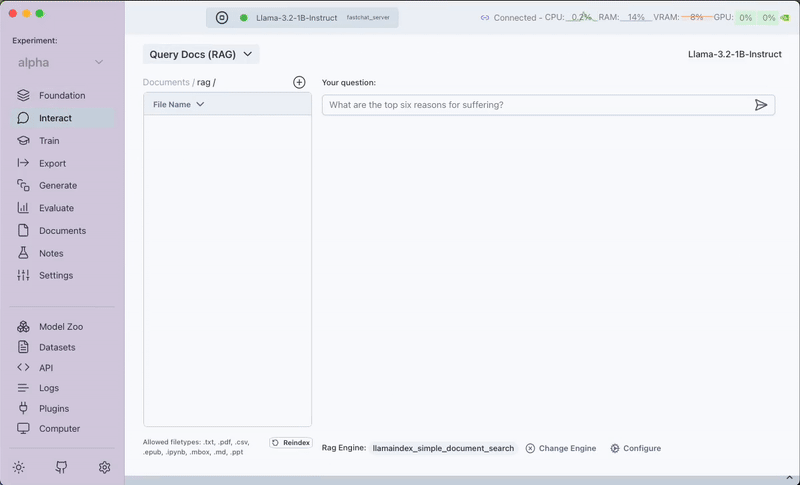
Step 3: Access the RAG Interface
Navigate to the Interact tab and select the "Query Docs (RAG)" option from the drop-down menu.
Using RAG
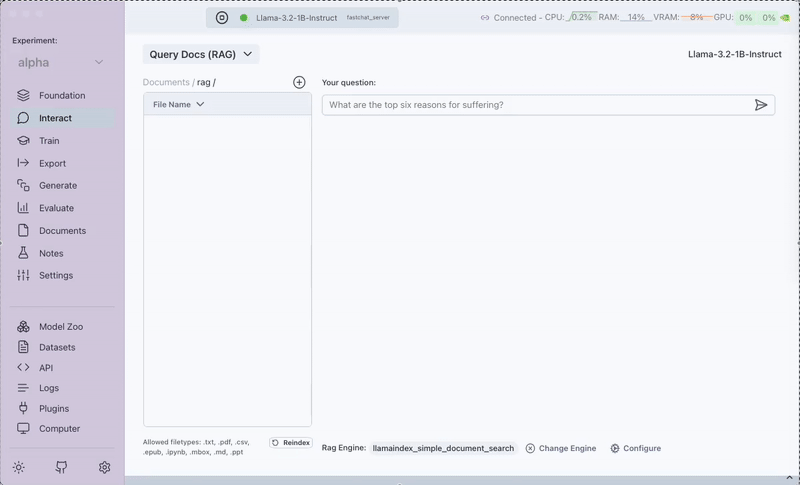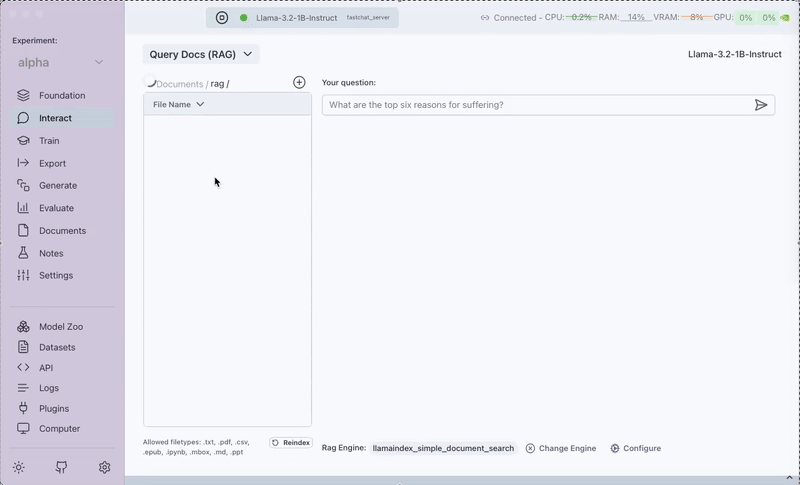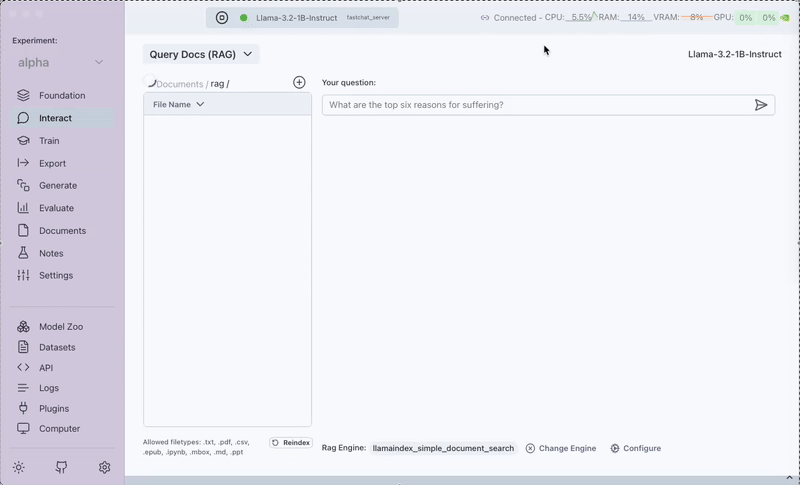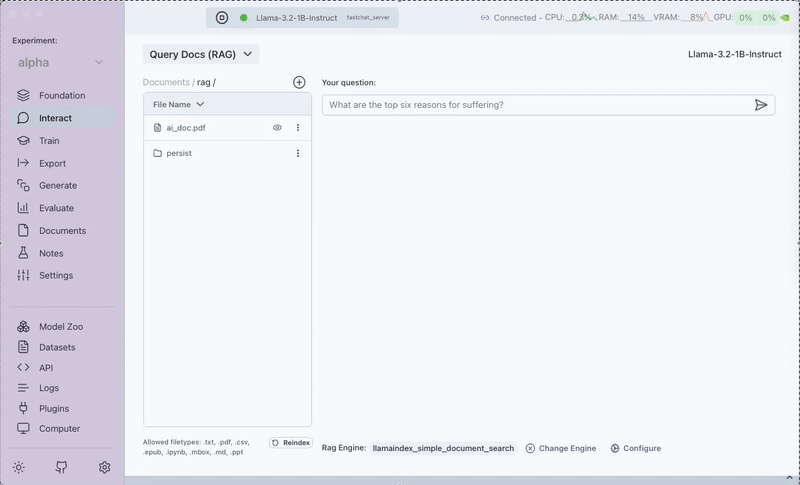
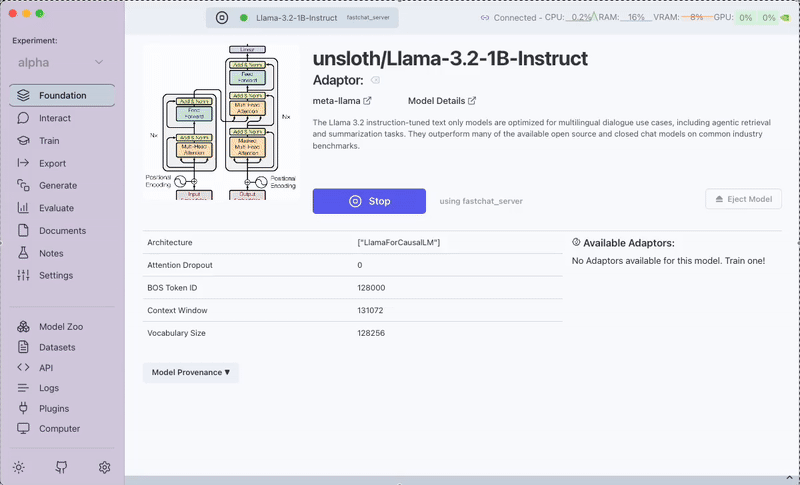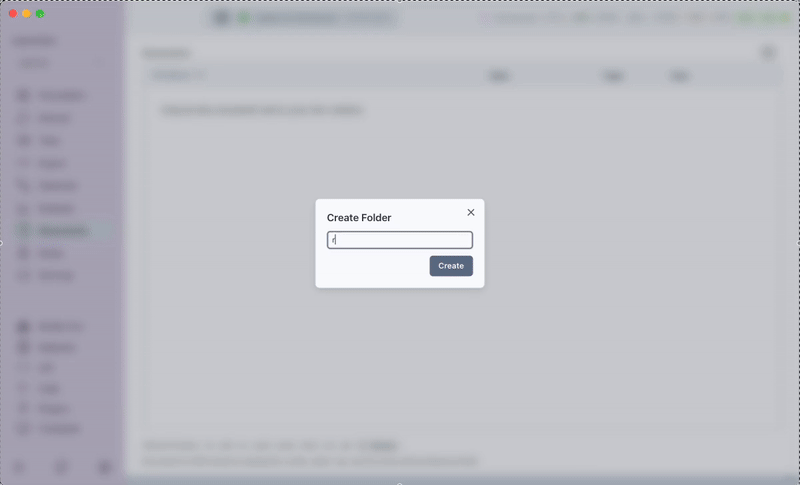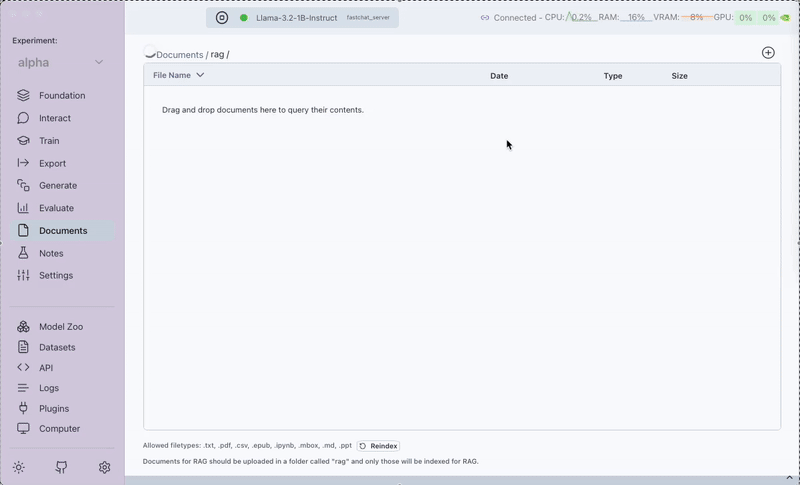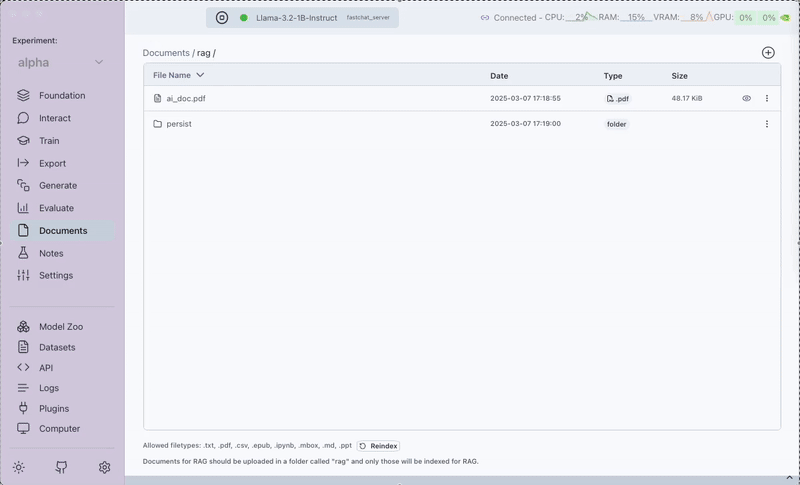
Step 4: Upload Documents
Within the RAG interface, you'll see the Documents tab on the left where you can upload files for indexing. Note: Documents can only be uploaded through this Documents tab.
Important note about document organization:
- Documents must be stored in a folder named "rag" to be indexed
- When uploading through the Documents tab in the RAG interface, files are automatically placed in a 'rag' folder
- When working outside of the RAG interface, you need to:
- First create a folder named "rag" in your workspace if it doesn't exist
- Upload your documents to this folder for them to be indexed for RAG
Step 5: Query Your Documents
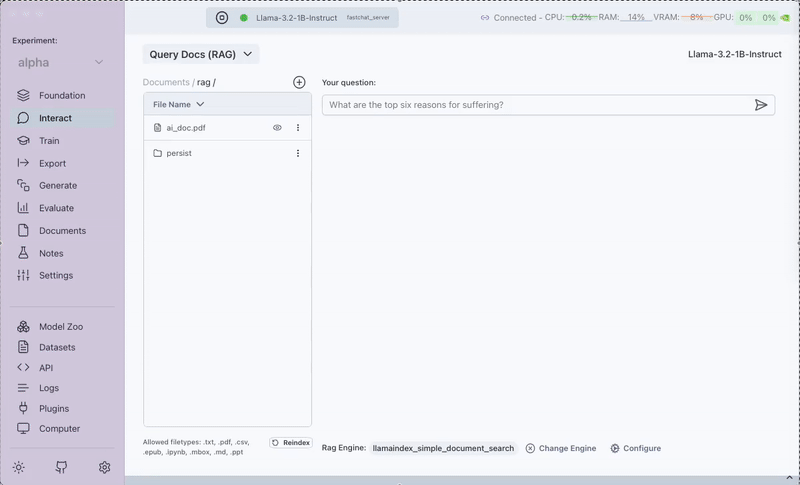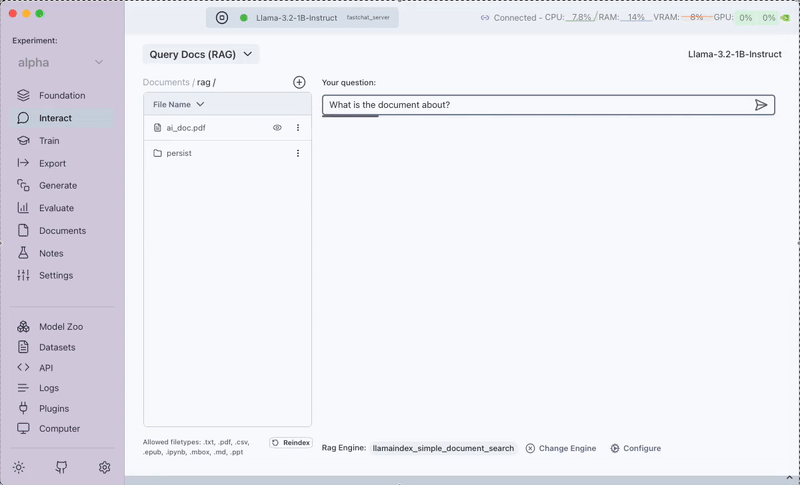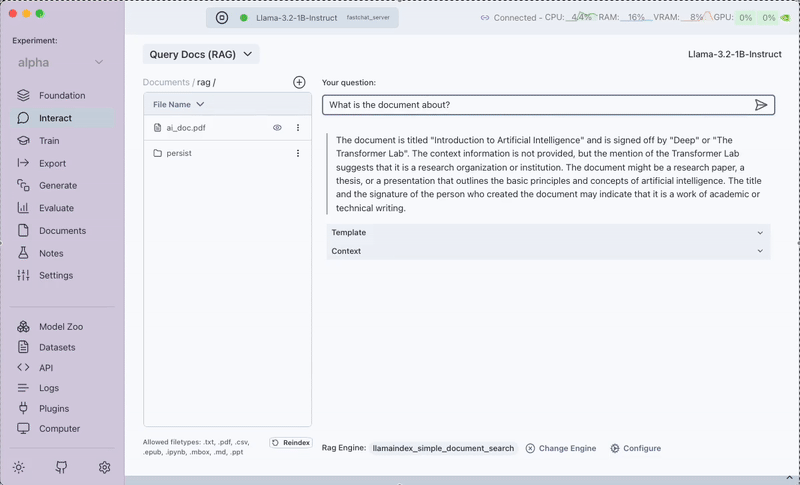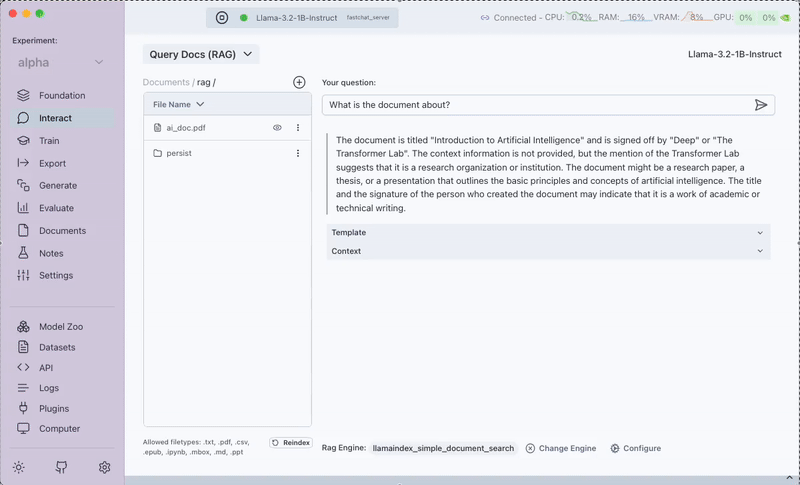
Once your documents are uploaded, you can ask questions in the text input box. The model will provide answers based on the content of your documents.
Results
The system returns:
- The answer to your question
- The prompt used to generate the answer
- The context (relevant document passages) used by the model
Current Limitations and Future Plans
- Currently limited to a single RAG plugin
- Documents must follow the "rag" folder naming convention
- Future updates will:
- Add flexibility in selecting folders for indexing
- Support testing different embedding models for improved retrieval