Model Activations
The Model Activations interface provides advanced insights into how a language model processes and generates text, allowing you to visualize internal mechanisms of the model's decision-making process.
Note: This feature is currently experimental and is only available to use with the Fastchat and MLX Server.
Accessing Model Activations
After running a model in the Foundation tab, you can analyze its internal workings:
- Navigate to the Interact tab
- Select "Model Activations" from the dropdown menu
Features
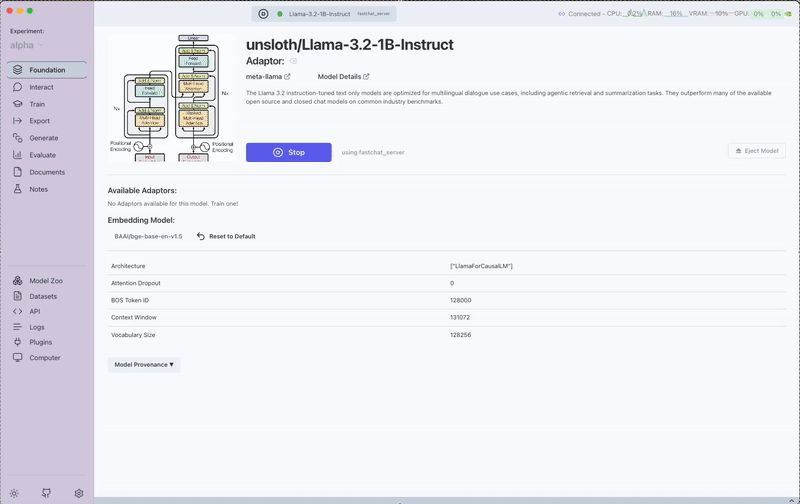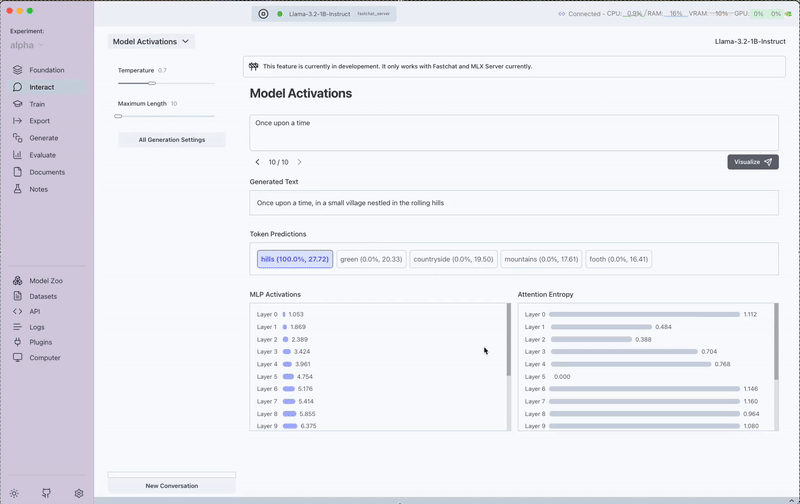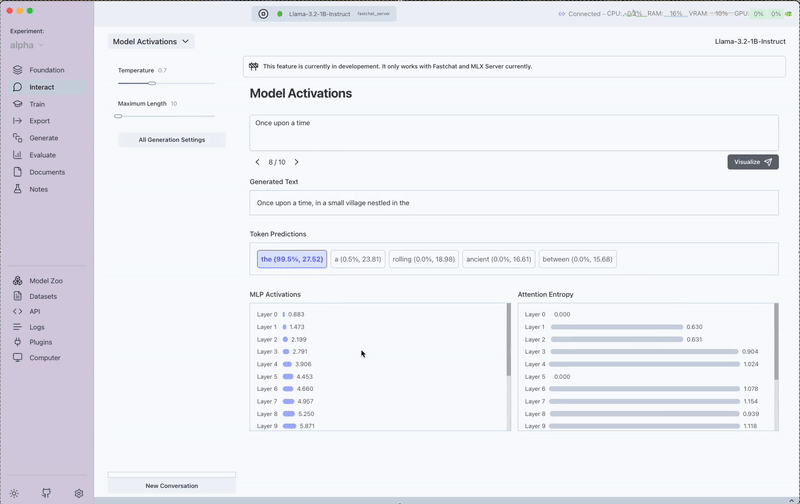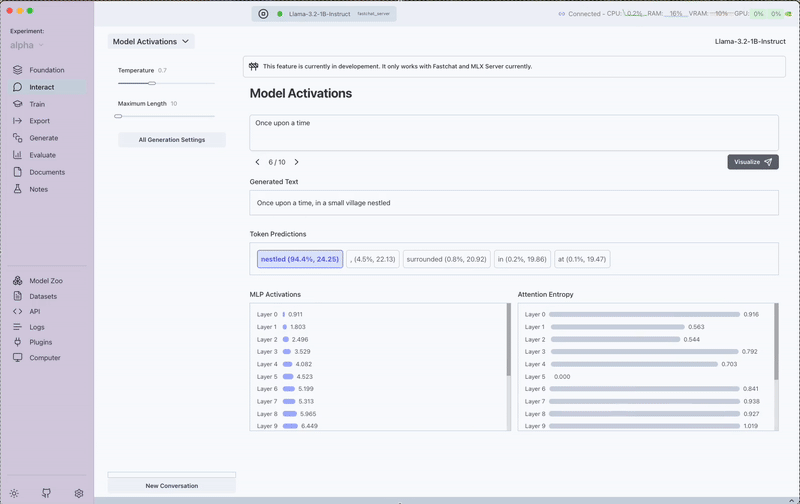
The Model Activations interface exposes three key aspects of the model's internal processing:
1. Token Probabilities
- View the probability distribution of the top words the model considered before selecting each token
- Compare alternative words the model might have chosen
- Understand how confident the model was in its selections
2. Layer-wise Activations
- Visualize activation patterns across different layers of the neural network
- Identify which layers are most active for specific types of tokens
- Gain insights into how information flows through the model
3. Attention Entropy Scores
- Examine attention entropy for each token
- Understand how focused or distributed the model's attention is
- Identify patterns in how the model allocates attention across different word types
Using Model Activations
- Enter your input text in the text box
- Configure generation parameters
- Click Generate
- Use the navigation arrows below the text box to step through each token
- Analyze the visualization panels showing probabilities, activations, and entropy scores for each token
Applications
Model Activations are particularly useful for:
- Research into model behavior and decision-making
- Diagnosing issues with generated text
- Understanding why a model produces specific outputs
- Teaching and learning about transformer architecture
- Fine-tuning prompt engineering techniques
This feature provides a window into the typically opaque processes inside neural language models.