Ollama Server Plugin
The Ollama Server plugin is our recommended plugin for running GGUF models across all platforms, and is the best way to use Transformer Lab if you do not have access to a GPU or a Mac Silicon-based system.
Ollama is the most popular application for running inference against open-source language models on your local machine. It works with GGUF-formatted models which allow for fast inference across both CPU and GPU. Users can take advantage of this to run models larger than their available GPU memory, and even run models entirely on CPU for systems without a GPU.
Chat using Ollama Server
Step 1: Install Ollama
In order to use the Ollama Server plugin you will need to first Download Ollama and install it on your system.
Step 2: Get GGUF Models
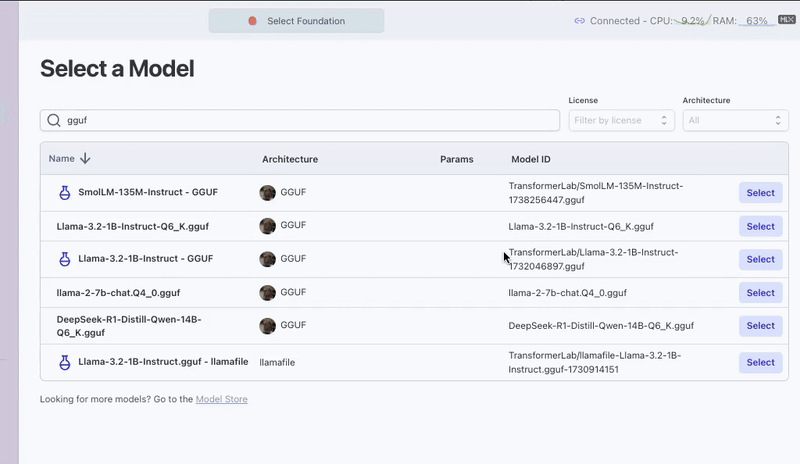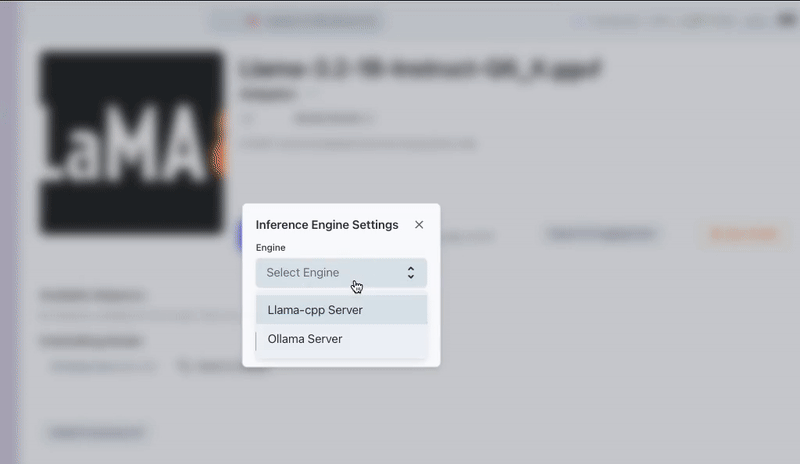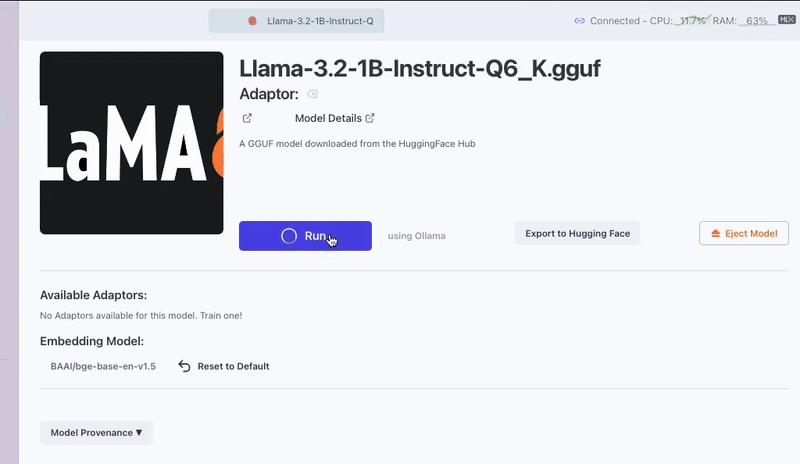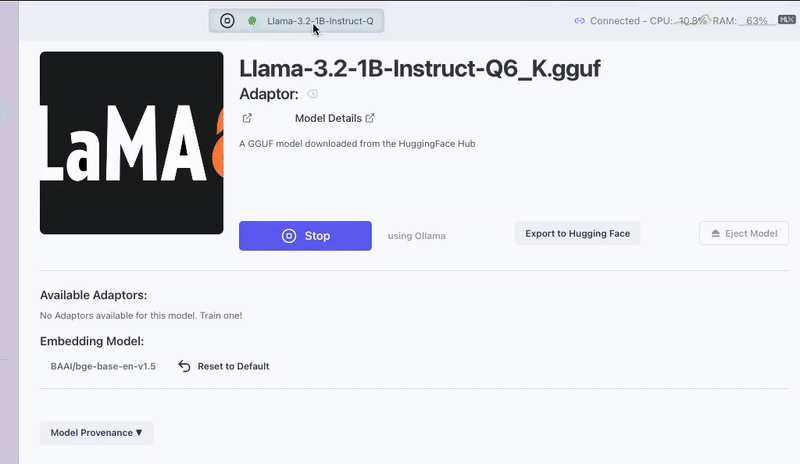
To use the Ollama Server plugin you will need to first downlaod a GGUF model. There are two ways to do this:
Download GGUF models from the Model Zoo: From the "Model Store" tab in the Model Zoo you can use the filters to select GGUF as the Archtecture to list some suggested defaults you can download. You can also find GGUF variations of most popular models on Hugging Face.
Import models from Ollama: If you have already installed Ollama and downloaded models there previously, you can easily import these models into Transformer Lab by going to the Model Zoo and selecting the "+ Import Local Models" button at the bottom of the screen. This should automatically detect any models available to import. After importing these models you will be able to find them on the "Foundation" tab.
Step 3: Select Ollama Server as your Inference Engine
On the Foundation tab, select the GGUF model you want to serve and, before clicking the "Run" button, check that your Inference Server is set to "Ollama Server". This can verified and changed by looking directly to the right of the "Run" button on the Foundation screen. To begin chatting with your model, click "Run" and navigate to the "Interact" tab.